

The fact is, he was showing his results as if they were accurate measurements of the researched feature, while for a journalist it should be very important to be able to keep a critical attitude toward whatever "result" is discussed - especially those one can extract by oneself by automatic means.
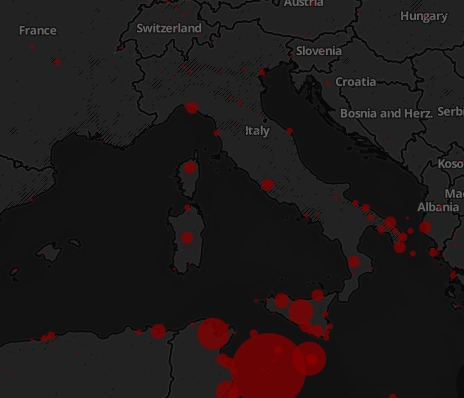 I took his web page where he was showing data for migrants killed in trying to reach Europe, and in a few clicks I got to see some of the original "data" entries which were the basis of the map his software had produced.
I took his web page where he was showing data for migrants killed in trying to reach Europe, and in a few clicks I got to see some of the original "data" entries which were the basis of the map his software had produced. The third one I browsed was a newspaper article on the French magazine "Liberation", who discussed how a migrant had slipped on a stone while washing himself on the beach, and died.
So I could point out to the speaker - and to the audience - how as a scientist I have a reverence for the data, and I pay extreme care to avoid any spurious entries in a dataset I use for some analysis. The Liberation piece, included in the automated search for "migrant killed", was an example of how an automated search collecting data for killed migrants was liable to produce a biased result and how spurious data could easily make it into the analysis.
In the end, it boils down to the fact that a scientist values (or should value) more the error bar around an estimate than the estimate itself, as an estimate without error bar is more useless (and potentially deceiving) than an error bar without a central value: the latter tells at least something precise about the accuracy of the measurement, while the former says nothing at all.
I do not know whether my point was understood by the audience - I played the arrogant scientist, and I know I did not excel in sympathy when I do that. But it was on purpose: if they drove home the fact that they should be more skeptical of what is erroneously or deceivingly called "raw data" by their peer (or even by scientists who should move on to some more suitable occupations in their lives) I did not waste my listeners' time.
A couple of days later, it was the turn of Ayelet Baram Tsabari, who discussed "Using the web to analyse and increase people's interest in science". She discussed in detail how "Google trends" can be used to extract information on the interest of internet browsers in scientific topics based on their search terms and the graphs that the site provides. It was again my turn to play the hard-nosed professor of statistics as I interrupted her when she was showing one of those trend graphs, which had a large peak in coincidence with an important news event, and then a small secondary peak very close to it.
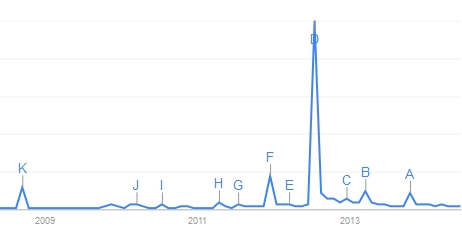 Although the proposed explanation for the secondary peak looked quite plausible, I felt compelled to explain that since Google trends only provides relative frequency graphs - the original absolute numbers are hidden - one can hardly associate an error bar to the graph, and thus a "feature" one observes in the graph cannot, in general, be taken as proof that something particular has occurred causing people to search for a particular term.
Although the proposed explanation for the secondary peak looked quite plausible, I felt compelled to explain that since Google trends only provides relative frequency graphs - the original absolute numbers are hidden - one can hardly associate an error bar to the graph, and thus a "feature" one observes in the graph cannot, in general, be taken as proof that something particular has occurred causing people to search for a particular term.(By the way, can anybody guess what is the search used in google trends to produce the graph above?)
My comment was not understood by the speaker, who referred to the graph as "the data" while I tried to explain to her that it was not raw data but a statistic (a statistic is a function of the data). She insisted that it was not a statistic, and I decided that her punishment would be to have her live with her ignorance... But I believe the discussion did allow the listeners to bring home the point - which was again the former one: data without an error estimate can only be taken as qualitative indications, and prove nothing in general.


Comments