

In spite of being smaller than the nucleus of all atomic elements (except Hydrogen, which is it), the proton is a very complex object. It is composed of quarks and gluons, lots of them; and actually, the composition depends on the magnification power of the "microscope" with which you observe it: the higher the energy of a collision, the smaller is the wavelength of the virtual "light" with which we illuminate it; and as the wavelength diminishes, you see more and more quarks and gluons.
How can we calculate the probability that a quark or a gluon from one proton will hit a similar quark or gluon in another proton and create, say, a Higgs boson, if we do not even know how many of these particles exist in the proton ? In fact, we cannot. We cannot calculate the probability to find a quark with such and such characteristics in a proton traveling at a given energy.
When we cannot calculate, we physicists do not despair, though: we create a mathematical model of what we think is the answer, and then we collect data - lots of it. By fitting the model to the data, we extract the model parameters, and there you have it: the models can then answer your questions.
What I am talking about are called Parton Distribution Functions, PDF for insiders: these are functions we use to model the unknown probabilities. We write them as, say, xg(x,Q^2), where x is the fraction of the proton's energy that is carried by the parton in question (in this case a gluon, g) and Q^2 is the energy at which we "probe" the proton. I will not explain here why we multiply g(x,Q^2) by x, nor why the PDF of the gluon depends both on the fraction of energy it itself carries and on the total energy of the collision - this would take a series of posts, not one. But I can explain, at least, what is the present status of things with our modeling of the PDFs, as we get ready to analyze data produced at a Q^2 value so far never reached.
Enter the paper "The PDF4LHC report on PDFs and LHC data: Results from Run 1 and Preparations for Run 2". This is a very thorough and detailed study by a group of experts - both phenomenologists and experimentalists - who analyzed the situation of our knowledge of the proton PDFs, what are the main uncertainties, how the LHC Run 1 data improved the models, and how we can improve the situation with Run 2 data.
The paper is 40 pages long, but it is not too hard to read - perhaps the good mix of authors created the right conditions for a well written document. It contains lots of very interesting bits, and I am quite embarassed to have to single out one or two of these for this blog; anybody who is interested in the matter, or any graduate student who plans to measure a cross section in Run 2 at the LHC, should read it.
Let us take the picture below. It is a figure (figure 2 in the paper, in fact) showing what is called the "parton-parton luminosity", i.e. the convolution of the PDF of two projectiles to create a massive state (of mass M_X, in the abscissa). What is plotted on the y axis is the ratio between some PDF model (CT, MSTW) and the "reference" NNPDF set (in green). What you see is that the agreement between these three different models (on the top graphs for quark-quark luminosities, and on the bottom for quark-antiquark ones; the left graphs refer to an older version of the models, the right ones to the newer version) has generally improved in the new PDF fits.
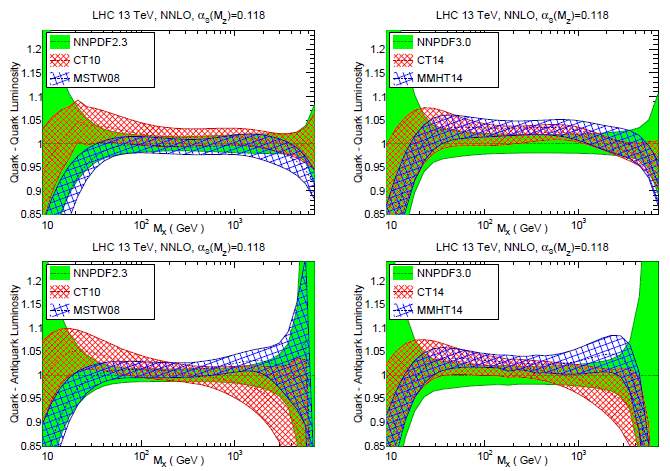
More technical conclusions can be read in the paper, but here I would like to draw your attention to a simple fact: we know very little of the probability to produce a massive state above, say, 3 TeV. The reason is that the LHC Run 1 data could provide inputs whose statistical power "died out" right there. We will certainly push the limit up with the new data, but here I draw your attention to the fact that the relative uncertainty, from PDF modeling alone, with which we know the cross section of Standard Model backgrounds, rises quickly above 10% for the heaviest mass region. What this means is that we will have a hard time discovering new particles at that high-energy end, given our insufficient knowledge of the proton PDF: if we see an excess in the data we might be tempted to call it a new resonance, but we will always have to reckon with the fact that we cannot be sure of the real behaviour of the PDF at the very high end.
Something similar happened to CDF in 1996, when an excess at high energy of the cross section of inclusive jet production got many excited, as it could be the first signal of small constituents within quarks. Later it was discovered how the PDF model used was insufficiently precise, and the data returned in agreement with the new predictions.
But let's not be discouraged - what everybody hopes in fact is that we'll hit some pretty unmistakable new physics signal in Run 2, one which no PDF uncertainty could explain away. I remain sceptical, but I would be among the first to celebrate...



Comments