

The Vth MODE Workshop took place in Kolymbari (Crete) June 8-13. MODE is a collaboration I founded in 2020 and directed until last year. MODE stands for "Machine-learning Optimization of the Design of Experiments". It is a group of 40 institutions across three continents which look at ways to use new AI technology to produce breakthroughs in the way we imagine the particle detectors of the future. The workshop is a small and unpretentious event - we got 50 participants this year, with an average age well below 30 years - but we like it that way as it is a great setting for focused discussions on really interesting collaborative research.
This year the program included updates and insights on a number of exciting new AI methods. One of special relevance involved the automated design of interferometers for quantum experiments: a software that selects setups of lasers, mirrors, and semi-reflective surfaces to create measurement capabilities from the resulting interference patterns. Another talk I liked was one that discussed reinforcement learning for optimal experiment design; one of the use cases it showed results for was the same one we are studying with diffusion models - the optimization of the layout of a sampling calorimeter. The speaker (Shah Ruck Qasim) showed how reinforcement learning can be used with profit on such a problem.
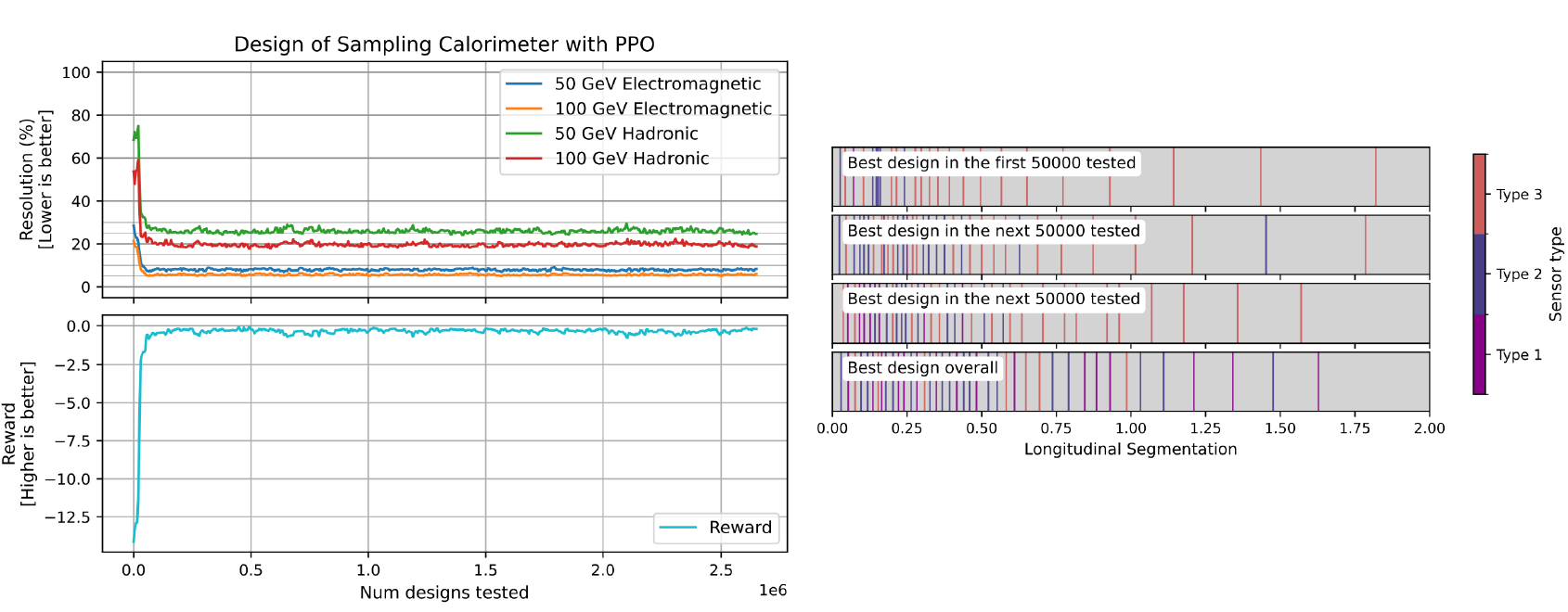
Above: Evolution of sampling calorimeter layout during the search
The studies presented by my students (see picture below) included applications of neuromorphic computing for tracking and calorimetry, particle identification capabilities of granular calorimeters, and end-to-end optimization of calorimeters for future colliders.

Above: with my students participating to the MODE workshop
Given that the workshop is titled "Differentiable programming for experiment design", one could question what supervised classification for particle identification has to do with that. But indeed, determining what are the asymptotic capabilities of software tools in extracting particle ID from the topology of the energy deposition of hadrons in a highly granular instrument is a necessary preliminary step to the optimization of these devices: by determining at what granularity scale (the size of individual detector elements capable of independently recording energy deposition and time of interactions) that information is accessible, is a very important input for future calorimeters. You can see below, e.g., how the discrimination power (vertical axis) gets washed out as the volume of cells grows (the horizontal axis), for particles of energy between 25 and 100 GeV hitting a PbWO4 based detector.

Above: accuracy of pion/proton discrimination versus number of calorimeter cells
After the MODE workshop, I traveled to Cagliari for the second EUCAIF conference. EUCAIF (for European Coalition for Artificial Intelligence in Fundamental Physics) is a relatively new player in the area of synergies of AI with research in physics. About 250 participants gathered in Cagliari to discuss recent advances and to organize common activities. EUCAIF spawns five working groups, that aggregate efforts in foundation models, co-design, fairness and sustainability, infrastructure, and community building. Together with Pietro Vischia, I am chairing the Working Group 2 on Co-design of future experiments.

Above: with a few more students at the EUCAIF conference
At EUCAIF I was rather depressed to note that I was the oldest participant (!). I guess that kind of thing will happen more and more often in the future, but at 59 years of age I thought this was not yet going to be the norm... But AI conferences are a place for young people, indeed. I should probably switch to numismatics or philatelics, when I am quite confident I would be among the youngest.
EUCAIF was a great place to learn about a number of new studies. Here the talks were not specifically about experiment optimization, and they focused on advances in methods that can be game changers in all our research tasks, including of course software methods. I invite you to browse through the many talks that were presented there, at this link.
In the session I convened for Working group 2, we found ourselves pondering on the fact that the co-design paradigm - the idea that a true full optimization of an experiment requires to jointly optimize the hardware eliciting data from physical processes and the software extracting information from the data - is easy to define but not so easy to prove in practice. Indeed, I am not aware of any fully convincing proof of the advantage of joint optimization of hardware and software.
What I would like to produce is a simple study of a use case where:
(1) if you design in a humanly conceivable way the hardware, and then apply some appropriate software reconstruction, you can obtain a result which corresponds to a utility X_1 (the larger, the better). The definition of X could be the inverse of the uncertainty on a parameter you want to measure, for example.
(2) if you optimize the software extracting a measurement based on the humanly designed hardware, you can then obtain a utility X_2 which will be larger than X_1.
(3) if you instead optimize the hardware, but retain the "reasonable" software for inference, you might obtain a result with a utility X_3. X_3 will be larger than X_1, too, and could be larger or smaller than X_2 depending on the use case.
(4) if you proceed with optimizing the software based on the optimized hardware obtained in (3), you could then reach a utility X_4 which will be larger than X_3, and almost certainly larger than X_2, too.
(5) If you instead use the co-design idea and optimize jointly the hardware and the software at the same time, your utility X_5 at the end of the day could be larger than X_4 (and a fortiori all others). Why? Because the simultaneous optimization of all parameters of a system guarantees that you have access to the full search space, which is instead restricted whenever you perform the optimization in steps.
Now, while the above is conceptually not too difficult to explain (I indeed tried to do it in less than 20 lines of text), it is actually not easy to produce in a concrete example. The general difficulty is that a system that is not complex enough will not exhibit a strong coupling between the details of hardware functioning and software reconstruction, making serial optimization as good as a simultaneous optimization. Another issue is the fact that the software step, if dealt with by a sufficiently capient neural network, could also remove the need for simultaneous optimization.
I have therefore started to think deeply on the matter. I am still convinced that physical systems where X_5 > X_i (i=1,2,3,4) do exist, and will try to come up with one example...


Comments