As I reported a couple of times in the course of the last three months, the ATLAS experiment (one of the two all-purpose experiments at the CERN Large Hadron Collider) has launched a challenge to data analyzers around the world. The task is to correctly classify as many Higgs boson decays to tau lepton pairs as possible, separating them from all competing backgrounds. Those of you who are not familiar with the search of the Higgs boson may wonder what the above means, so here is a crash course on that topic.
Crash course on the Higgs and its decays to tau leptons
The Higgs boson is the particle discovered in 2012 by the ATLAS and CMS experiments, by colliding proton beams accelerated to the unprecedented energy of 8 TeV by the Large Hadron Collider. The new particle was predicted a full 50 years ago by a few theorists to explain the observed characteristics of the subnuclear world, and its discovery is a true success of physics.
The Higgs boson decays immediately after it is produced, by yielding two other particles: two W or Z bosons, or two photons, or two quarks, or two leptons. Physicists try to detect and measure all these final states, in the hope of characterizing as well as possible the new particle from its decay products. One of the important final states is the one including two tau leptons. The tau lepton is a heavy version of the electron, and unlike the electron it decays very quickly -in less than a picosecond- yielding lighter particles. Its detection and correct identification is complex, thus the reconstruction of the decay of the Higgs boson to two tau leptons is also complicated.
The CMS and ATLAS experiments have already been able to detect Higgs boson decays to tau lepton pairs, but the complexity of the analysis leaves room for improvement. Hence ATLAS thought that by challenging data analysts around the world to correctly classify the signal in a mixed sample containing lots of background events (not due to Higgs decays) it could be possible to gather new ideas on how to improve the performance of the classification algorithms used by the experiment.
The challenge
To participate in the challenge one does not need to be a particle physicist: in fact, one just needs to be reasonably well-versed in the use of computers and statistical algorithms for classification. At the kaggle site of the challenge the user is provided with two large csv files (numbers separated by commas).
The first file, containing 250000 lines, is a table of 30 measured characteristics of "events" - particle collisions, simulated as the ATLAS detector would measure them. Some of these are Higgs decays to tau leptons, others are background events that look similar to the signal. The last number in each line tells whether the event is a signal or background one, so that an algorithm can be trained to distinguish the two possibilities based on the value of the thirty measured quantities.
The second file contains 550000 lines, and has the same format except that no information on whether each line corresponds to a signal or a background event is given. This is the sample of data that the user is asked to classify.
Once the user produces an answer - which is a third file with a ordered list of the event numbers from the second file, and a classification bit ("1" for signal, "0" for background), he or she can submit the result to the kaggle site, obtaining an evaluation of how good the classification was. This is measured with a metric called "approximate median signficance" which roughly corresponds to the statistical significance that the selected data classified as signal would yield.
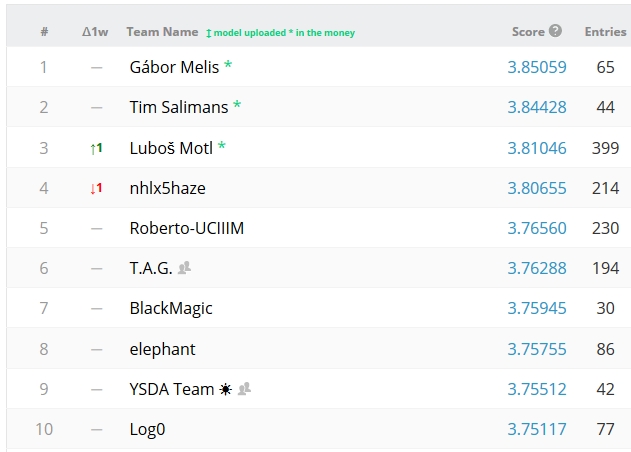
If you look at the "leaderboard" of the Higgs challenge web page you can see that there is a total of over 1200 participants. The three best classifications will be awarded money prizes totalling $13000. At the moment, the three leaders of the challenge include the blogger and ex theoretical physicist Lubos Motl, a fact which I find remarkable - Lubos is not a data analyst by training, so he is demonstrating his universal skills here. I do hope he will win a prize, even more so now that it has become increasingly likely that the winner will have a final AMS score exceeding 3.80. A couple of months ago Lubos bet $100 that such a high score would not be achieved - but he recently surpassed it himself! On the other hand, one should note that the final scores may be different from the ones listed in the leaderboard, as they will be computed with 450000 of the 550000 submitted test events; the leaderboard numbers instead are based on the first 100000 ones.
I should also mention that I am not just a bystander: I took the challenge as a nice opportunity to test an algorithm of my own cooking, which is based on the "nearest neighbor" idea. I have no ambition to fight for the prize, but the setting was ideal to test the performance of different choices in the working of my algorithm. You can find my name in the standings list currently as the 377th position, with a AMS score which is however not bad at all for a non-boosted, weak-learning classification method. I wish I could have more time to work on it, but I guess my standing is not going to improve in the course of the next month, which will be the last one of the competition.



