


How is this for some exciting news, straight from the same source as “I Let My Computer Use My Brain” three years ago, but much advanced in the ways artificial intelligence (AI) has integrated itself further so that most anybody can now work with it, or better, play with it and do cutting edge research nevertheless (UPDATE: this is now also featured on the Wolfram website):
“Technology belongs to macro-evolution; this includes the inevitable integration with artificial intelligence (AI). There has been much hype and misunderstanding around AI and the concept of evolution, hence, many may suspect our tossing fancy catchphrases. We are well aware of this and nevertheless take that risk, for one because of the way in which the computer helps intelligently today, the naturalness in which the “programming” via graphical user interfaces (GUI) and ‘interpreted languages’ has already become an almost informal, playful chat with the machine. This is part of the long hyped transition, and it becomes finally obvious what “artificial intelligence” actually is, namely, not news to general, algorithmic evolution, in much the same way that nanotechnology is not news – the terms “artificial” and “technology” merely reveal anthropocentrism.” [full reference and directfree access see below]
This is from a straight forward, scientific article providing novel, extremely easy and adaptable solutions to diverse problems, but the reason for why that all works so well is the correct philosophy; this is the main claim! The work is indeed as much about philosophy as it is about computer image analysis, dirty programming, or complex nanotech structures – useful, scientific philosophy of course, but Darwinist philosophy and sociology nevertheless!
The guiding philosophy is Bio is Nature's Nanotech, and it is about no less than witnessing what some call the "Singularity" (Singularity: Properly defined andsubstantial Criticism):
“Our methods here are not so much a great intellectual achievement than a symptom of a transition that happens with or without us; we are early adopters at most.” [from “1. General introduction, guiding philosophy: Bio is nature’s nanotech”]
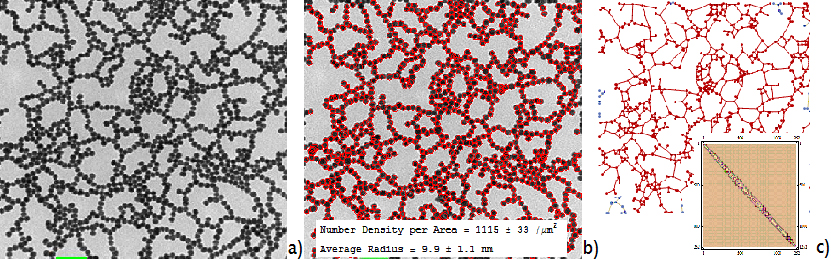
Figure Caption: A microscopy image (a) of a network of metal nanoparticles is analyzed, without marking being required except for the scale bar (bottom left, marked green). The computer finds all particles that are not intersected by the image borders (b). Therefore, the accuracy of the surface coverage ratio (see inset) can be established by automatic reanalysis of segments of the image. The size distribution of the nanoparticles’ radius is immediately available. The connection graph (c) is provided and neighborhood network statistics, such as the Kirchhoff-matrix (inset), are also immediately calculated. The Kirchhoff-matrix is necessary for predicting the thermal and electrical resistance between network nodes and therefore useful to predict optical properties.
Computers help nanotechnology; this seems as boring and obvious as one could get, however, this particular, widely applicable research methodology has been developed straight from the “Bio is Nature’s Nanotech” guiding philosophy, whose main interest are very general complex systems and their emergent properties as they evolve (by environmental selection) in their multi-dimensional parameter spaces (“design space” in the evolutionists’ terminology):
“As nanoscience becomes true nanotechnology, nano-materials characterization fails to keep up with the almost biological complexity of the nano-nano and nano-micro hybrid structures that it now starts to produce. Many readers may object already, because microscopy is traditionally close to biology and well developed for it, and biology is nature’s nanotech! Nanotechnology is not news to Mother Nature, who adapted through developing an astounding variety of nano-reproducers and catalysts for example, namely enzymes, whose properties are adaptable mostly via the shapes that enzymes fold into. Thus, issues like the nanotechnologist’s obsession with shape and size effects are not as novel as we claim them to be. That biology is nature’s nanotech is here not idle philosophy but relevant for several reasons. In short,
You cannot stop evolution.
Evolution is all about getting ahead with what bio-evolutionary scientists call “kludges”.
Biomedical research can therefore inform nanotechnology.
Let us clarify these in order to make our general approach understood. (1) You cannot stop evolution; we have no choice in these matters. Nanotechnology participates in evolution, it evolves, and required adaptation to rapid environmental changes also demands a future nanotechnology with capabilities that approach biology in terms of rapid adaptation by efficient means to design complex nano-micro-hybrid structures. Because of the necessity of improved energy and resource (oil, rare metals) efficiency, the development of nanometer scale catalysts, especially for energy applications, is one of the most important topics globally. Also with today’s nanotechnological catalysts, hierarchical structure plays an increasingly important role, say via porosity that gives access to high index surfaces and lattice dislocations, metal-metal interfaces and metal-matrix support interactions, but also shape changing (almost like some enzymes), i.e. truly nano-mechanical systems in the future. It is thus important to efficiently analyze the structure of complex nano-micro compounds and to be able to predict growth processes and emergent properties like fractal dimensions in order to produce and optimize structures with desired properties. In other words, we leave physics behind and start to become more like biologists. Even if one could reduce everything to physics in principle, it is practically impossible and further rapid progress in nanotechnology must overcome its present “physics envy”. This leads us to the second item
(2), namely efficient naturally selected systems being a hopelessly complex bunch of kludges, of “dirty little tricks” that just happen to survive well. As technology evolves, the technology itself also becomes like this, not just the systems we synthesise, but the methods we use. It is important to this work here, because we freely mix simulation into analysis stages, even making use of the strengths of neural network computations via the human’s visual system, and our computation is “fast and dirty programming” that without a doubt makes professional programmers cringe. Unashamed, we hold this, of course with stringent testing (just like natural selection), to have not only become possible today but superior now, precisely what is needed, and we believe that our results support this. …”[1]
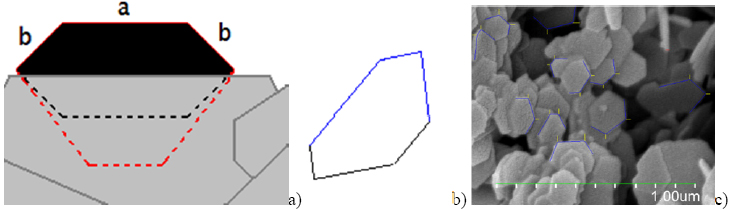
Figure Caption: Computer assisted image analysis determines accurate shapes and sizes in spite of random rotations with unknown biases due to alignment on top of the microscopy substrate and mutual stacking of the flat shapes on top of each other. (a) A shape (black) is largely hidden (below grey areas) due to stacking. It could be a truncated triangle (TT) that lies almost flat in the image-plane (red hatched line), so that a is truly longer than the adjacent sides b, or a regular hexagon (black hatched line) rotated out of view, so that the neighboring sides merely seem shorter. Distinguishing these would ideally need lengths a and b, and two Euler angles. (b) The analysis algorithm was tested with simulated and thus precisely known images, revealing division-by-zero problems. We must mark three adjacent sides (blue) having two included angles. (c) Part of marked SEM ready to be fed to the improved algorithm.
The whole approach is through and through, in all its aspects, in accordance with the guiding philosophy, and for example, AI does not only enter by the amazing capability of imagere cognition today – that would not be AI integration in the sense of what the singularity is all about -- but via the way we humans have come to compute, namely basically by playing games with the AI in Darwinist ways:
“We never first study details such as which entry from the table the expression “[[i,j]]” extracts. We observe what the program outputs when using slightly modified lines of code. This is fast and more efficient also in regards to learning the language. We developed much of the desired programs step by step trying out modifications, always inputting small parts of a few of the images to be analyzed. Explaining the code any further would be detrimental to the message: One does not need to.
Of course, insufficiently understanding one’s tools is dangerous. Simulation easily becomes a virtual reality different from physical one. However, researchers unfamiliar with programming lack time to study what a command such as “ComponentMeasurements” does in detail (it is a sophisticated morphological image recognition algorithm). Complex systems are understood sufficiently for well defined purposes through rigorous testing. Testing includes simulated test images, the parameters of which are known precisely so that the image recognition’s errors become known precisely. There will always be some debugging, but it never yet involved problems with, say, sequences of “#” and “&”, because they were copied from working programs; modifications that output nonsense are immediately undone (die). In this manner, all parts, say the simulation of test images and the desired statistical analysis are added to the program one by one, short parts of code, usually two to five lines, which behave similar to the desired behaviour, followed by modifying and rigorous testing.” [1]
The book chapter is available at the direct link below – no pay wall.
--------------------
Reference:
[1] S. Vongehr et al.: Computer Assisted Microscopy Image Analysis for High Throughput Statistical Analysis and 3D Structure Determination in Nanotechnology. In: A. Mendez-Vilas (Ed.): Microscopy: Advances in scientific Research and Education Formatex Microscopy Book Series 6(2), pages 618-625 (Sep 2014)
ISBN(13): 978-84-942134-4-1 http://www.microscopy6book.org/
Direct link: http://www.formatex.info/microscopy6/book/618-625.pdf



Comments