


How vision operates is a complex task thehuman brain (and now “computer brains” have to take on). We take much of whatour brains do for granted.
For instance, there is depth perception, object tracking, differences in lighting, edge detection, and many other features that our brains keep track of. Scanning the environment and localizing where we are in space is an undertaking that our brain is constantly doing. In some point in the past, researchers may have never thought it possible to create systems that can perform similar tasks to that of our own brains. Yet, in the last 50 years, we have gone from what might seem like small steps in neuroscience to computers being able to describe scenes in pictures.
There are plenty of anecdotes that are taughtduring a neuroscience course to help students understand how the brainfunctions, for instance Phineas Gauge getting his left frontal cortex destroyedby a railroad rod and surviving or Britten’s paper depicting when the brain can detect asignal in a chaotic mess of moving dots. Such insights are likepuzzle pieces, allowing us glimpses of how the brain operates.
Human vision research owes much to Hubel and Wiesel, who were given the Nobel Prize in 1981 for their work in psychology. They had made groundbreaking “discoveries concerning information processing in the visual system.” By connecting an electrode to a neuron, they were able to listen to the neuron responding to the stimulus of a bar of light.
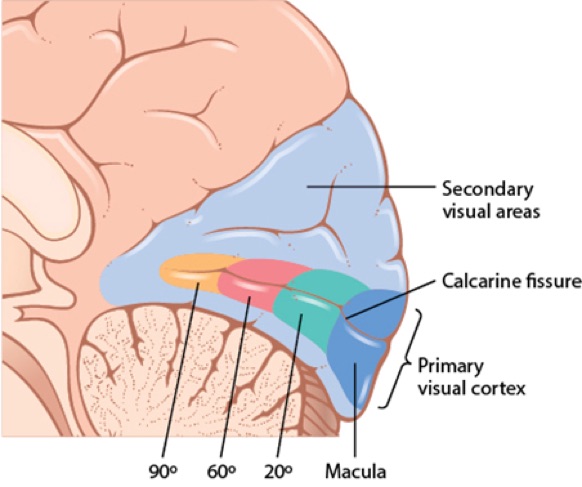
The researchers gained an understanding of how neurons in the primary visual cortex (which can be seen in the image above) operated. It was mind blowing. In particular, they discovered that there were three different types of neurons that responded to different stimuli.
They classified the cells into three groups, simple cells, complex cells, and hypercomplex cells.
A simple cell would respond to a stimulus if it matched the angle of light which lined up with the cell’s excitatory region.This can be seen in the picture below and figure b.
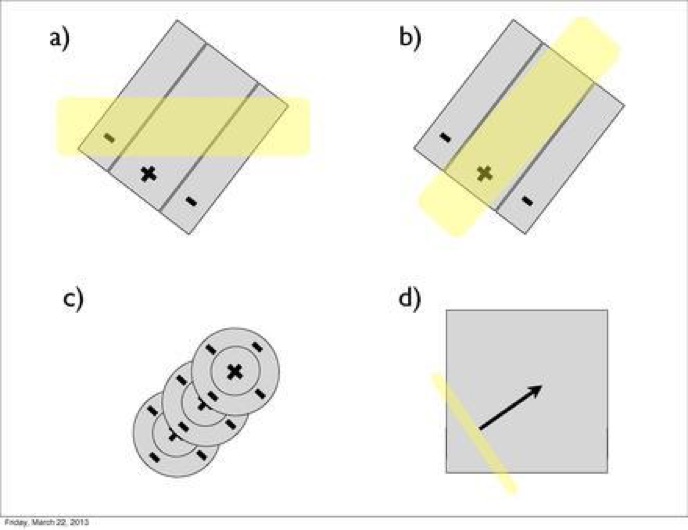
A complex cell not only requires the correct angle, but also requires the stimulus to be moving. This is the most prevalent cell in the primary visual cortex, also known as the V1.
Finally, hypercomplex cells have the same qualities as the previous two cells. However, there is one more requirement.Hypercomplex cells require orientation of stimuli, movement, and direction of movement. So, a hypercomplex cell might respond to a stimulus at 90 degrees that is moving from left to right, but not right to left.
This video below depict how neurons in the brain only respond to bars of lights in specific locations and at certain angles. As the bar of light was moved, there is a crackle: You are hearing the neuron of a cat respond to the stimulus.
With this experiment, the researchers demonstrated how several types of neurons were activated only under certain stimulation. Another fascinating feature was the fact that the cells seemed to naturally map for different angles. In other words, each section of V1 would contain a very specific set of neurons that mostly responded to bars of light with a specific angle.
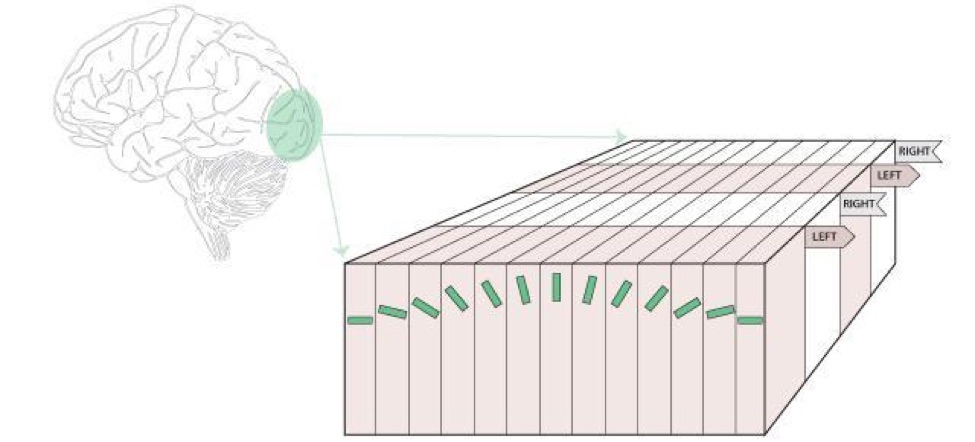
These results led to the theory that, by creating a sort of “bottom-up image” of the world, the human brain can “draw a picture” of what’s going on around us.
Fast forward nearly 30 years to BA Olshausen and DJ Field, two researchers in computational neuroscience. This is the study of how the brain encodes and decodes information. Instead of just focusing on single bars of lights, this team focused on how a statistical model could recognize edges and other low level features in a natural image.
Natural images have predictive features like edges, shadows, and other low level features that help our brains discover depth, e.g., where one object ends and another begins. Being able to locate these features help our brains make sense of the world around us.
One of their seminal papers, Natural Image Statistics and Efficient Coding, was written back in 1996. The purpose of it was to discuss the failures of Hebbian learning models in image recognition, specifically the utilization of principal component analysis.
Now science has gone from detecting bars of lights with a cat’s neuron, to a mathematical model of a network that outputs actual features from images.
The last line of the 1996 paper stands out:“An important and exciting future challenge will be to extrapolate these principles into higher cortical visual areas to provide predictions.” This was the challenge: to create models that could take neurons that could detect edges that were currently being modeled by various computational research scientists and then create a bottom-up network that could actually predict the context of an image.

The outputs of Olshausen and DJ Field model were similar to the one above.
If you are a deep learning fan, then this matrix of outputted lower level features looks familiar. This is a similar set of features that is utilized in a convolutional neural network.
The next article will discuss the jump from detecting features of images, to the classification of objects using convolutional neural networks.



Comments