

There is a lot at stake. Even leaving aside the Higgs hunt for a second, just imagine you are looking in a specific dataset for a high-mass new particle which most likely does not exist: you want to place "upper limits" on the mass M of the particle which are more stringent than previously published analyses. This is done by reconstructing the tentative mass of the particle in your selected events, producing a histogram of these masses; then when the histogram is compared with the expected background, one can say "at this mass M, the signal is smaller than x events, or else I would have seen it". Of course the statistical analysis does a more careful thing, but the idea is the one I described.
You can then put a dot in a graph where the horizontal axis is the mass, and the vertical axis is the rate; the dot will be placed at x for mass M. You connect the dots for all masses and you get a "upper limit" curve, which basically says "tell me a mass hypothesis, and I will tell you how large can the signal rate be since I have not seen it". Finally, you compare that curve with a curve that theorists computed: that is the predicted signal rate as a function of mass. If the curve is higher than your limit, you have excluded that theory, because you did not see such a large rate of signal events; if the theory is below your upper limit, you cannot exclude the particle. So in the end you can place a "lower limit" on the mass M of the particle: this is the mass for which the theoretical rate prediction crosses your upper limit curve.
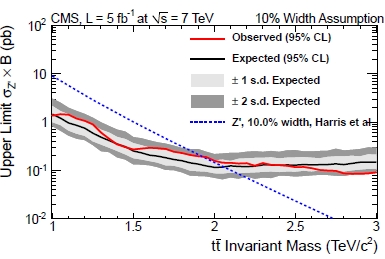 The graph on the right shows precisely what I described, for the case of a search of a Z' boson in CMS (a result based on 2011 data). The red curve is the upper limit, the dashed curve is the theory prediction. (In the graph you also see the 1-sigma and 2-sigma bands around the expected limit, which basically explain whether the data showed an upward or downward fluctuation with respect to expectations based on the absence of a signal). The intersection is at 1.95 TeV, which is the lower limit on the Z' mass from the analysis.
The graph on the right shows precisely what I described, for the case of a search of a Z' boson in CMS (a result based on 2011 data). The red curve is the upper limit, the dashed curve is the theory prediction. (In the graph you also see the 1-sigma and 2-sigma bands around the expected limit, which basically explain whether the data showed an upward or downward fluctuation with respect to expectations based on the absence of a signal). The intersection is at 1.95 TeV, which is the lower limit on the Z' mass from the analysis.Now, if you miss the ICHEP deadline, and your competitors (the analyzers in the other experiment, e.g. CMS if you are in ATLAS or vice versa) make it, your result is likely to become obsolete overnight: once everybody knows from the other experiment that the particle you look for has a mass M larger than X GeV (the limit set by your competitors), your result will not be worth a publication on one of the top notch scientific magazines if you end up excluding a mass range M<Y GeV and if, because of bad luck or worse analysis or detector, Y happens to be less than X ! If, on the other hand, you and your competitors both present your results together, there will be interest in both results.
But for the Higgs things are red-hot now. We all know that, after the firm evidence (but let us remember that Professor Strassler objects strongly to this qualification of the winter 2012 results, and who am I to contradict him and his polled colleagues) of a Higgs boson with a mass in the 124-126 GeV range came out, there is a chance that the Summer 2012 results which include the fresh new 2012 data will produce conclusive proof of the existence of the Higgs.
So both ATLAS and CMS are frantically tuning their analyses these days, and in the process of adding the latest data. I mentioned the fact that the analysis of the new data will not take long in a previous post, and I got questions on the process by curious readers in the thread. I answered in some detail on what is the difference between "spinning" the data and "reconstructing" the events there, and then I thought that the answer would be interesting to a larger pool of readers. So below I am reporting the answer, minimally edited.
---
"Spinning" (also called "analyzing") is when we take our analysis program and we get it to read all the (reconstructed) event files, producing final histograms and results. Reconstructing comes earlier, when raw data (from detector components, e.g. silicon hits and calorimeter energy deposits) is used to reconstruct physics "objects" like tracks of charged particles, muon and electron candidates, jets, photons, tau candidates, missing transverse energy, primary vertices.
The reconstruction phase takes much longer than the final analysis. One could very roughly say that one CPU takes O(1s) or even longer to reconstruct an event, while a typical analysis job will take O(1ms) to do even elaborate things with the event data. Mind you, I am not a software expert, so the above numbers can well be off by one order of magnitude or so; but they give the idea of the difference between the two phases.
Now let us take 5/fb of data (the amount so far collected by ATLAS and CMS from the 2012 running of the LHC) and ask ourselves what this means in terms of events. It is not straightforward to compute how many events that is: it would require knowing the exact output rate of events written to tape for all the different "data streams", each corresponding to the trigger system having accepted the event based on the presence of different candidate objects, e.g. muons or electrons, high-pT jets, etcetera. But very roughly, if 5/fb were taken in three months of data taking, with a duty cycle of 30% that is 3 million seconds of data written to tape at 300 Hz rate -> a billion events.
So you could eyeball that if a single CPU were to do the job, it would take O(1Gs), a billion seconds, to reconstruct the 2012 dataset; a thousand CPUs will take a thoursandth of that, i.e. two weeks. These are order of magnitude estimates, so they should be taken with a pinch of salt. Also, I am not taking into account the intermediate steps (calibration procedures need to be run to get the corrected energy estimates, for instance, and these require running calibration datasets first... But let's omit these details).
Now for the spinning: a Higgs to gamma-gamma search will only look at a subset of those billion events -those recognized to contain photon candidates. Say these are 50 million events: it will take half a day to produce results by "spinning" them, if you program takes 1 ms for each event, and if you run a single CPU. Again, these are very rough estimates and only show the "typical" time expense. For the Higgs to gamma gamma, for instance, in fact the analysis takes longer because there are some neural networks performing complicated energy corrections... Every analysis has its own bottleneck. But the orders of magnitude are the ones I described above.
One should also note that the LHC experiments are much more effective than earlier experiments in the reconstruction of data, both thanks to improved detectors and algorithms and to larger CPU pools. At the Tevatron I remember that the delay between taking a data event and having it available after reconstruction was of the order of four to six months; at the LHC things are much less painful.
---
So, the bottomline is the following: LHC experiments are working around the clock to present results of their searches on 2012 data; these results will be ready in two weeks; and there is a fair chance that the Higgs boson discovery will be announced in July !



Comments