What is multithreading? It is the use of multiple processors to perform tasks in parallel by a single computer program. I have known this simple fact for over thirty years, but funnily enough I never explored it in practice. The reason is fundamentally that I am a physicist, not a computer scientist, and as a physicist I tend to stick with a known skillset to solve my problems, and to invest time in more physics knowledge than software wizardry. You might well say I am not a good programmer altogether, although that would secretly cause me pain. I would answer that while it is certainly true that my programs are ugly and hard to read, they do what they are supposed to do, as proven by a certain record of scientific publications.
Yet multithreading today is unavoidable if you wish to exploit the power of multiple CPUs and GPUs the typical computing centers offer to a researcher who wants to do machine learning -and don't we all? In the specific, the reason why I have not acquired expertise with it is a compounding one: I continue to doggedly stick with C++ in my projects, while GPUs and ML "off-the-shelf" routines and libraries are written in and for the Python programmer.
Bear with me: I learned Fortran during the final years of my University studies, and that was quite an effort on my part (I was coming from an instant love for Basic, with which in the early 1980s I wrote tons of fun software projects). And then, all of a sudden the world of particle physics changed, and I was forced to learn C++ -arguably one of the ugliest computer languages around. I never learned C++ properly, but I slowly managed to do everything I needed to do for my daily work - data analysis.
In Fortran and then in C++ I wrote machine learning algorithms ante litteram, inventing a couple of techniques too. Those did not revolutionize the field in any way, and I did not became a Le Cun or a Hinton. But I had fun with them. And when in the early 2010s machine learning become what everybody wanted to do, all day, for the rest of their life, and everybody dove into advanced Python programming, I sailed on with my rudimentary but practical knowledge of whatever was needed to do my work.
The burden of sticking to C++, in a world where by using Python you can go from knowing zilch about programming altogether to training a neural network in the matter of an afternoon, is not an easy one. Everywhere I look I see kids a third of my age developing solutions faster than I can ever code them. But.
Doing things the hard way, without libraries that do everything for you, has its merits. You learn a lot, and get a lot of insight in what works, what does not, and why. When I hear kids talking about boosting, batch normalization, learning rate scheduling, momentum in stochastic gradient descent, and the like, I know that they are talking about setting a parameter in a routine they never looked into, while those concepts to me mean what they really are - for I coded them line by line at least once in my life. Does that make me an expert in machine learning? Well, in a sense, yes. Does it help my research work? Yes and no. It does in terms of insight, but it somehow hampers it when I insist in coding things from start to end rather than retrofitting my code with some external library (which entails having to learn what is inside it, at least for me).
But the world moves on fast, and I am more and more entangled in bigger and bigger projects. These require larger computing demands. And single CPUs will not do any more. This, e.g., applies to one of the projects I am working on, a differentiable programming model of the SWGO experiment. Oh, wait a minute - here I should make a detour to explain just how much of a dinosaur I am. Yes, differentiable programming - is that not the thing you can do with Pytorch or TensorFlow? Yes, but you can actually implement differentiable programming in C++, too!
What is not fun is to compute derivatives by hand. I am spending hours to compute and recompute pages and pages of formulas, to implement the derivative of some utility function in a software program I have been writing, which performs an optimization of the layout of the SWGO detector. The not-so-fun thing with derivatives of large functions is that if you do it N times, you are likely to find N different results. Of these, maybe half will indeed be the same, but they will still look different as algebric expressions... It is little short of a nightmare.
Enter DerivGrind. This is a software written by computer scientists in Kaiserslautern, which allows the user to compute in an automatic way the derivatives of complex pieces of software written in C++. In the previous post I described how I was taught by one of the authors how to include the relevant functionalities of DerivGrind in my code, which allowed me to test my calculations!
So I got past the derivatives nightmare, and now I have a piece of software that models in a continuous way the SWGO experiment, the atmospheric showers raining on it, and the reconstruction of the showers and the derivation of statistical inference, and the cycling over varied configurations of the detector, in search for the maximum of a utility function by stochastic gradient descent. My code has grown to be over 6,000 lines long, and counting. And it has become slow.
In the past, I could always solve the problem of slow computing by dividing the full task into smaller jobs, and then running many identical program each on a subset of the data, or on a subset of the assignment. This is a good practical solution in many situations, that allows you to exploit the multi-CPU clusters and speed up your tasks. But in the case of the SWGO optimization, this cannot be done - if I create multiple copies of the program, they will not manage to work coherently into finding where the utility is maximized.
What to do? I could try to find a student willing to convert the code into Pytorch, which would allow it to run on GPUs, parallelizing all slow calculations and making it lickety split. But first of all, I would hate an advisor that does something like that; and second, frankly such an operation would be hard for anybody, leave alone the average physics student.
After dragging my feet as much as I could, I decided to look into how to make my C++ program a multi-threading one. That would solve the problem, as I have easy access to multi-core clusters of computers, and a speedup by a factor of 20 or 30 or even more could be easy to reach, without any need to use in-high-demand GPUs. But how? Well, I asked ChatGPT. I had to put together a descriptive question that explained the boundaries of my problem, the fact that there were two parts of the code where a parallelization would be useful, and a few other issues concerning data access and handling.
And when ChatGPT spewed its answer, in less than 10 seconds, I looked at the screen in disbelief. Could it really be that easy? The whole thing would boil down to adding an #include command at the beginning of my source code, and then embed into functions the two parts that could be parallelized; a synchronization command would suffice to restore single-threading at the end of each fan-out.
I tried to complain with the machine, arguing I could not figure out where in the code snippet it had provided was the command that detailed access to the CPUs. The machine patiently explained that it was all transparent to the user! The next split second I started to write a test program. I finished it in 3 minutes, compiled it, linked it, and run it. It worked. In 10 minutes I had the solution in front of my eyes. I wanted to cry.
To cut the story short, I am now happily exploiting multithreading to run simulations of the SWGO experiment. What took a night to compute on my laptop until a week ago, now takes 10 minutes on the cluster of computers I moved to. Here is a fun bit - the "top" command that you can use on linux machines to check the status of different jobs, and which reports the %CPU used by each, thus reports the load caused by my job:
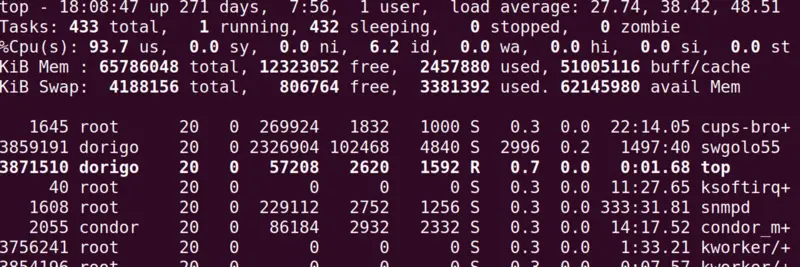
As you see, the job named "SWGOLO55" (second line in the table of jobs) is taking 2996% of CPU time in the cluster - as I asked for a parallelization of the CPU-heavy routines into 30 cores. Duh.
Now, there is another reason why the above is a good solution: right now everybody is on vacation, and I practically have the full computing cluster for myself. When my colleagues get back from holidays I will have to move my running to a virtual system I can instantiate on a different computer cluster (without affecting anybody else), otherwise all other users would be unable to do much computing on the same cluster I am using.
So, to summarize: the world has moved to Python, but you can still live a comfortable life with C++, and you are not losing much. You still get access to automatic differentiation tools (which are the engine under the hood of 95% of all machine learning methods), and can still exploit parallel processing. I think the sabbatical I was considering, to study Python once and for all, is getting far, far away...



