Mind readers have long been the domain of folklore and science fiction. But some new findings demonstrate the power of computational modeling to improve our understanding of how the brain processes information and thoughts and it brings scientists closer to knowing how specific thoughts activate our brains.
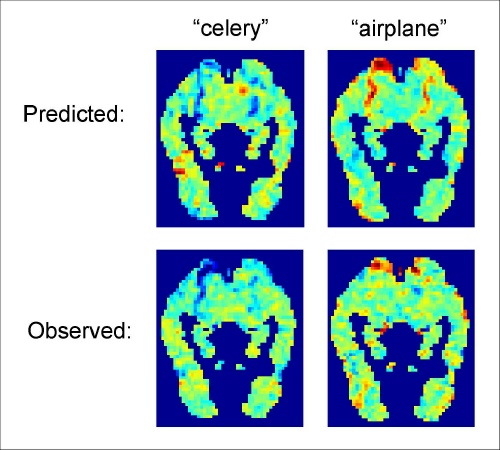
In their most recent work a computer scientist, Tom Mitchell, and a cognitive neuroscientist, Marcel Just, both of Carnegie Mellon University, used fMRI data to develop a sophisticated computational model that can predict the brain activation patterns associated with concrete nouns, or things that we experience through our senses, even if the computer did not already have the fMRI data for that specific noun.
The researchers first built a model that took the fMRI activation patterns for 60 concrete nouns broken down into 12 categories including animals, body parts, buildings, clothing, insects, vehicles and vegetables. The model also analyzed a text corpus, or a set of texts that contained more than a trillion words, noting how each noun was used in relation to a set of 25 verbs associated with sensory or motor functions. Combining the brain scan information with the analysis of the text corpus, the computer then predicted the brain activity pattern of thousands of other concrete nouns.
In cases where the actual activation patterns were known, the researchers found that the accuracy of the computer model's predictions was significantly better than chance. The computer can effectively predict what each participant's brain activation patterns would look like when each thought about these words, even without having seen the patterns associated with those words in advance.

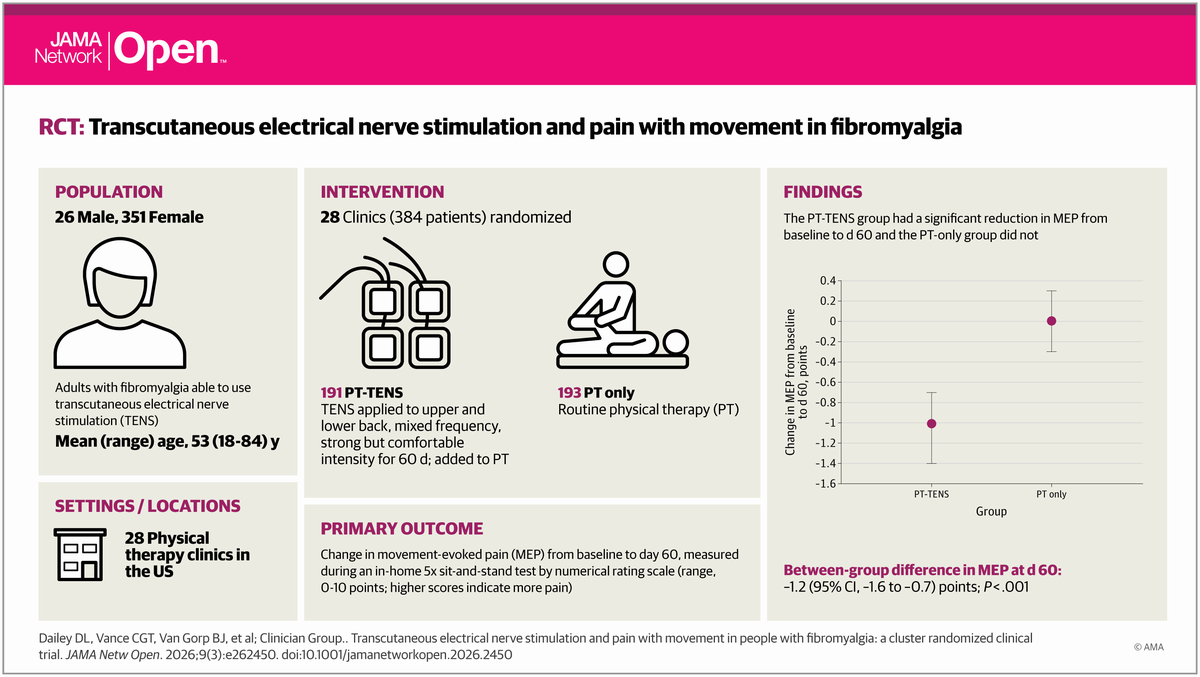 Pilot Study: Fibromyalgia Fatigue Improved By TENS Therapy
Pilot Study: Fibromyalgia Fatigue Improved By TENS Therapy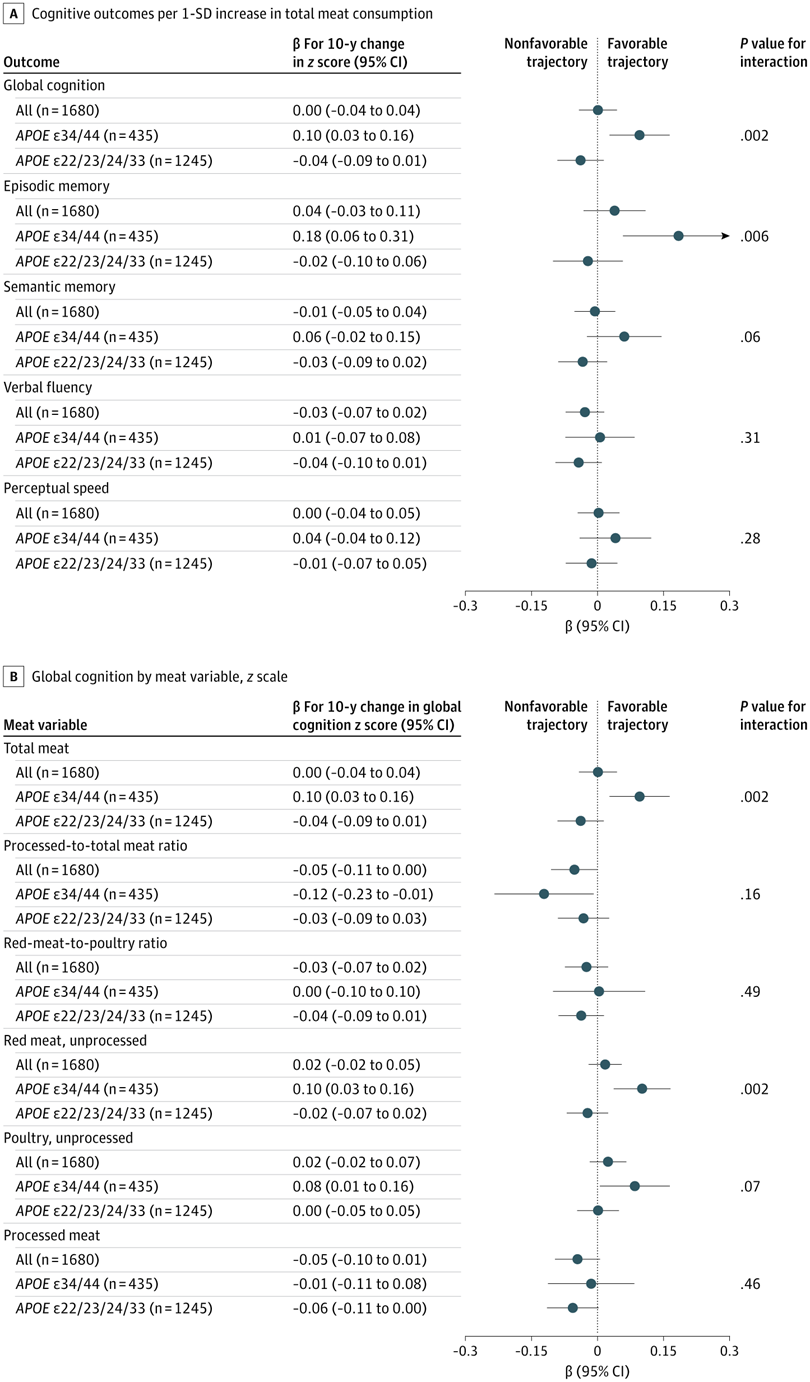 High Meat Consumption Linked To Lower Dementia Risk
High Meat Consumption Linked To Lower Dementia Risk Long Before The Inca Colonized Peru, Natives Had A Thriving Trade Network
Long Before The Inca Colonized Peru, Natives Had A Thriving Trade Network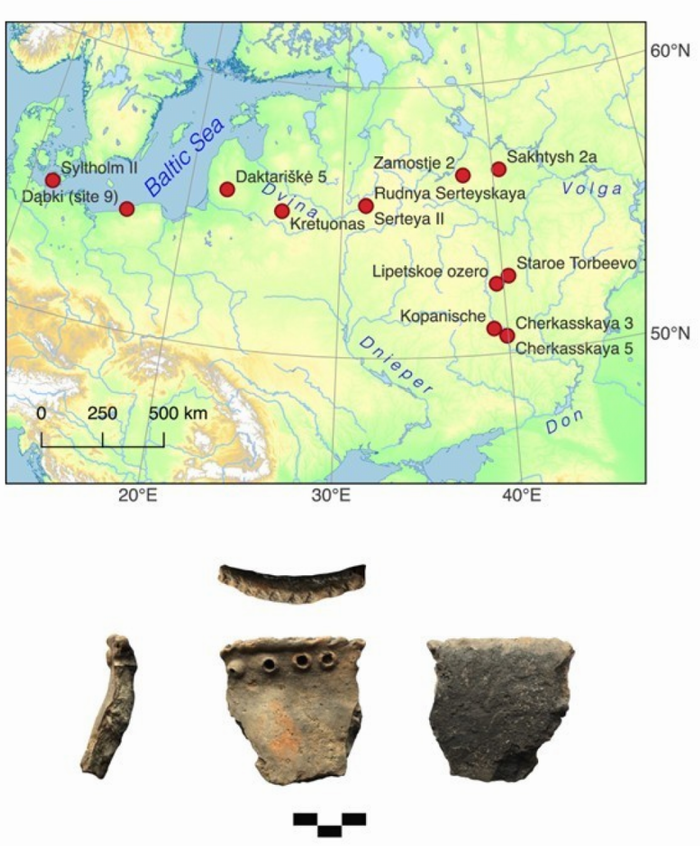 Mesolithic People Had Meals With More Tradition Than You Thought
Mesolithic People Had Meals With More Tradition Than You Thought










