

One of the things I like the most when I do data analysis is to use "pure thought" to predict in advance the features of a probability density function of some observable quantity from the physical process I am studying. By doing that, one can try one's hand at demonstrating one's understanding of the details of the physics at play.
The chance of entertaining oneself with this kind of exercise is ubiquitous in particle physics, as there are heaps of variables one can construct from the detector readings. It should go without saying: we measure millions of electronic channels for each proton-proton collision in the ATLAS and CMS detectors, and with those readings we reconstruct the trajectories and energies of hundreds of particles.
Of course, one then focuses on "high-level quantities", capable of summarizing the essence of what the collision produced: jets, electrons, muons, maybe two-body masses and relative angles. Still, the number of meaningful variables is large, and the probability to observe a certain value for each of them is not straightforward to predict. So the game is on. If I tell you I triggered on events based on the presence of identified electrons with transverse momenta above 20 GeV, and I am confident that the purity of the resulting electron candidates in the collected events is of about 80%, can you tell me what is the distribution of electron transverse momenta I should be looking at ?
The answer is not that hard. Real energetic electrons are produced in proton-proton collisions by two main processes: the first is W and Z boson decay, and the second is the decay of heavy-flavoured quarks. The former are less frequent, but they are concentrated at higher transverse momentum - the electrons should have transverse momenta peaking at half the mass of the W or Z boson; the latter are instead predictably most frequent at low momentum, as dictated by the steeply falling probability of finding collisions of higher and higher energy. So you should be looking at a steeply falling distribution, starting at 20 GeV (your transverse momentum threshold at trigger level), with a hump at 40 GeV or so due to the W and Z decay contribution.
See ? It is not too hard, really. And it can be extremely useful, also - if you take the attitude of predicting the features of a graph before producing it you are much more likely to make good use of it, as any feature you did not predict beforehand is either going to teach you something you did not know, or a signal of something in need of more investigation. This is how discoveries are really made!
After this lengthy introduction, let me describe a challenge presently on among myself and Pablo de Castro Manzano, the ESR we hired at INFN-Padova within theAMVA4NewPhysics network. The other day we were discussing the features of the data that CMS collected by a trigger that selects events with three or more energetic jets containing a b-tag. The issue is: if we select events containing four or more jets from this sample, and require that there be at least three jets with a medium b-tag and at at least a fourth with a loose b-tag, how pure of b-quark jets will the resulting sample be ?
The above question has some relevance to the search we are performing for production of pairs of Higgs bosons, with H->bb decays of both. Of course the signal always features four b-quarks in the final state; the issue is what are the features of the competing background, once one enriches of b-quark-jets the data sample with the above b-tagging recipe.
In order to find out the purity of b-quarks of jet events in the data, we can resort to a Monte Carlo simulation of Quantum ChromoDynamics (QCD) processes that do *not* contain Higgs pair decays. The study of the simulated events allows us to verify how often jets which are b-tagged are actually due to light quarks or gluons. Such "spurious" b-tags are unavoidable even for a very accurate b-tagging algorithm; one usually in fact chooses the working point of the algorithm by a trade-off between the efficiency with which it identifies real b-quark jets and the rate at which spurious b-tags are generated. The medium and loose working points of the b-tagger are one possible choice for our analysis, although not necessarily the final one; still, the question is meaningful for at least one reason.
The knowledge of whether the QCD background is constituted by b-quark jets or not, and in what fraction, is crucial for a data-driven modeling of that process. If the background after b-tagging is still rich in non-b-jets we can model it by studying samples with light quarks; otherwise things will be harder. Maybe this will be explained in a future post here. For now, let us concentrate on predicting the purity of the data in terms of b-quarks.
What Pablo and I agreed to do was to produce a set of predictions for the sample composition in terms of the number of b-quark jets among the four leading b-tagged ones: what are the relative fraction of jets that have 4,3,2,1, or 0 b-quark jets ? To make the game more interesting, we decided to divide the data according to the total invariant mass of the four jets in four bins from 200 to 1000 GeV: the purity may vary as a function of the total mass, so it makes sense to make a differential prediction.
In the end each of us produced a set of 5 fractions per each of the four mass bins. We decided to round these up to the closest 5%, and we also decided that the winning prediction will be the one which minimizes a chisquare test statistic. This can be computed once Pablo will have spun all the QCD Monte Carlo, obtaining the true values of b-jet fractions. If we call T_i(M_j) the true fractions, with i going from 0 to 4, and P_i(M_j) the predicted fractions, where j runs on the 4 mass bins, the test statistic is
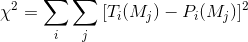
that is, a simple sum of squared deviations of the 20 fractions. One could have devised a more involved recipe, but arguably it does not matter - the result is only good for deciding who wins a beer.
Do you want to play with us ? Then let me be more specific. The data are a QCD simulation of CMS -collected proton-proton collisions at 13 TeV, and they pass the following requirements:
- trigger selection: three jets above 90 GeV, three online b-tags
- four-jet selection: at least four reconstructed jets with Et>20 GeV, and pseudorapidity in the -2.5 : 2.5 range
- at least three "medium-CSV" b-tags among the selected jets
- at least one "loose-CSV" b-tag among the selected jets remaining after removing the three jets with highest CSV value
That is it. Place your bets! I do promise to offer you a beer if your prediction is better than mine. You just need to post in the comments section a string of 20 numbers from zero to 1, in four rows of five, each set of five summing up to 1, thus:
- 200<M<400 GeV: F_0, F_1, F_2, F_3, F_4
- 400<M<600 GeV: F_0, F_1, F_2, F_3, F_4
- 600<M<800 GeV: F_0, F_1, F_2, F_3, F_4
- 800<M<1000 GeV: F_0, F_1, F_2, F_3, F_4
make sure the F_i are rounded off to 0.05 precision. E.g.: 0.35, 0.25, 0.20, 0.15,0.05.
Have fun! That's the most important thing...



Comments