

Data is collected by collider experiments by a process of selection and storage which at first sight appears nonsensical to the outsider. Every second we produce a billion proton-proton collisions in the core of ATLAS and CMS, read out the detector with fast electronics, process the signals, and write to storage all the information about... 400 of them. Yes: of the one-billion events we produce, what we save to disk is 0.00004% of the data. What ? You probably think the above sentence contains a typo or two: it can't be true. But it is.
I like to explain the rationale of this extremely tight selection with a simple analogy. Imagine you are mapping the composition of the underground rock at a site. Your machinery can dig 10-meter-deep and extract samples of soil at different depths. You start sampling the ground at different locations and you realize that it has the same composition in the area you are studying, and the stratification is homogeneous: at the same depth, you find the same stuff everywhere. Now, somebody brings in a new machine that can dig 20-meter-deep. As soon as you put it in operation, you just give a glimpse at the composition of the first 10 meter of ground (which you know already!), but then go straight to the samples collected at the higher depths, as that is the information you are missing.
Likewise, physicists have investigated at length the collisions of lower energy that were produced by past accelerators. We know very well what happens when we collide 100-GeV, 500-GeV, or 1-TeV protons from past studies. We do not care much to repeat those studies, as we would learn almost nothing. With the LHC we are interested in the most energetic collisions only. But these are the rarest: the vast majority of the collisions we produce do not release 13 TeV of energy (the nominal kinetic energy that the two protons bring in), as what collide are quarks and gluons, not the protons themselves; and those constituents carry small fractions of their parent's momentum. So we are interested only in a small fraction of the data!
It is convenient that we only need to study a small fraction of the collisions, as it would be impossible to store in its totality the enormous amount of data that the detector produces every second. Rather, we have a trigger system that selects only the most interesting collisions, the ones where more energy was released (or ones where particles rarely produced appear).
The trigger of a hadron collider detector is an amazingly complex device. It works in stages. In CMS there is a "level 1 trigger" that has to take a very, very fast decision on whether the 20-or-so collisions occurred during one bunch crossing (there's one every 25 nanoseconds!) contain something interesting. Only if the fast electronics decides that there's something worth storing, the corresponding data is passed to the next level.
The next trigger level in CMS is called "high-level triggers", HLT. At HLT level another tight selection is made, which allows to go down from an input rate of several tens of thousand events per second to an output rate of 400 events per second. Again, tight selection criteria are applied to sort out the most interesting collisions; but here, since the input rate is much smaller than at level 1, there is time for a complete reconstruction of the events, by fast software algorithms.
If above I gave you the impression that we do not care at all about the events we discard, I must now revise that concept a bit. We do care - in fact, there are indeed interesting things to study there. One such search is the one for events with jet pairs of medium energy. The rate of processes giving this topology is so high that we have to discard all of those events at HLT level. But a new technique, called "data scouting", relies on opening up a parallel path through which we do not store all the event information about the collisions, but just a teeny tiny fraction of it.
It works as follows: if an event with jets that passes some criteria is observed at HLT, normally it would be discarded. But the data scouting path allows to store the four-momenta of the observed jets for all those events, and little more. The fact that we store so little information (ten kilobytes of information per event instead of half a megabyte) allows to output many more events - about a thousand per second. Of course then we can do very little with the scarce information. But one thing we can do is to compute the invariant mass of these jet pairs, and construct a mass spectrum.
It turns out that the analysis of that spectrum allows us to search for particles that could decay into jets in a mass region where previous experiments could not exclude their existence -for more or less the same reasons of high rate I mentioned above. The search is performed with methods not different from those of ordinary searches for dijet resonances in "regular" CMS data, although with simplified selection criteria, calibration procedures, and other minor differences. The dijet mass distribution obtained by CMS is shown below.
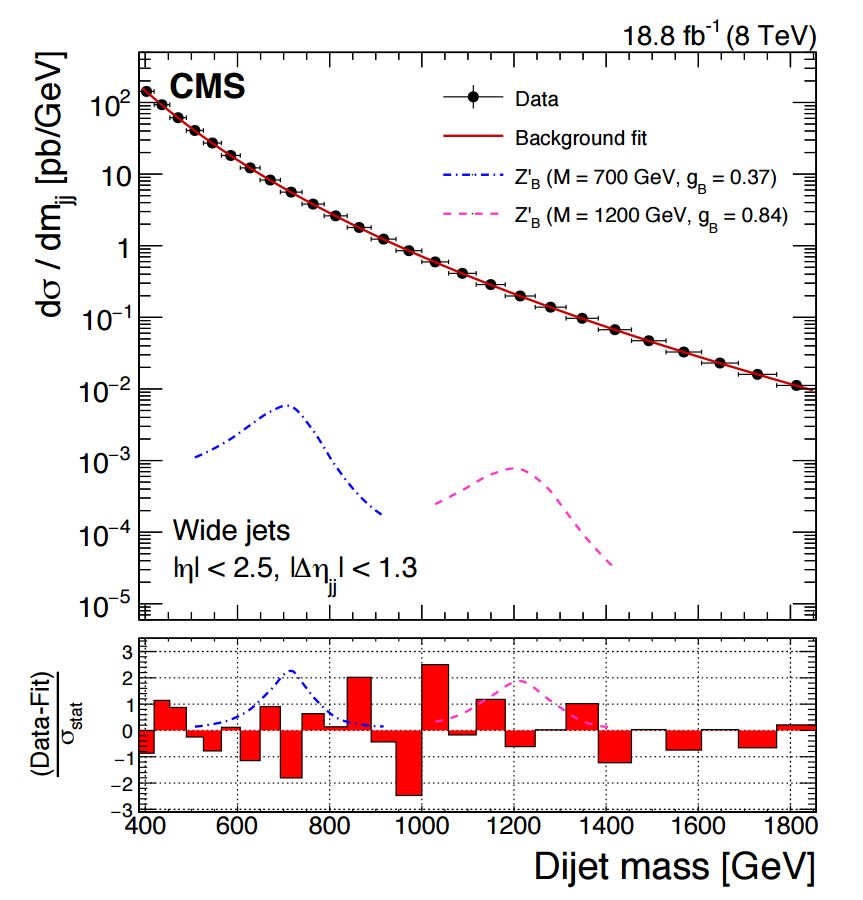
(Above, the upper panel shows the data (black points) as a function of mass, plotted not as number of events per bin but rather converting that number into the corresponding cross section. The lower panel shows the residuals of the data with respect to the background model, with overlaid two shapes corresponding to the possible signals one would see if there were a dijet resonance sitting at 700 or 1200 GeV, respectively.
The net result is that no dijet resonances have been found in these "scouted" data from the 2012 run of the LHC. The absence of a resonance is turned into an upper limit on the production cross section, and the latter in turn can be translated into an upper limit on the strength of a coupling responsible for the new interaction responsible for the particle creation. This is derived as a function of the hypothetical mass of the resonance. The graph is shown below, where you can see that the CMS data scouting technique allows the experiment to "reach down" into smaller coupling strengths which other past experiments, despite their "shallower digging" (remember the analogy I made earlier) could not investigate.
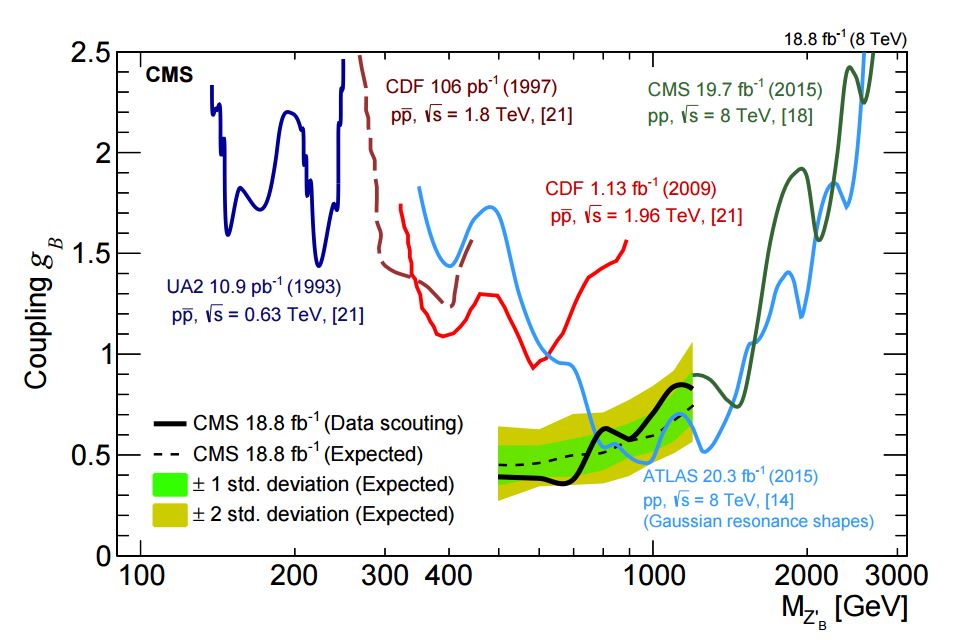
In the complicated graph above you see on the x axis the mass of a Z' boson, and on the y axis the strength of its coupling. Smaller couplings mean particles produced less frequently, so all the differently coloured lines in the graph are "upper limits" on the coupling as a function of the mass derived by different past experiments. These were obtained by verifying the absence of a particle signal - meaning that if the particle exists at that particular mass, it must be rarer than the limit on the coupling implies.
The thick black curve is the result of the data scouting analysis: you can see that in the 500-800 GeV region the limit is the most stringent, and more than twice so. The competing experiment at low mass is CDF, which used data collected at a collision energy four times smaller, when the collection of those "low-energy" dijet events was less demanding for the data acquisition system.
Having actively participated in the review process of this analysis I am especially happy to see the relative article coming to publication. CMS is showing high versatility in following unconventional paths to furthering the research in particle physics!


Comments