

All hadron collider experiments, such as those run by the CDF and DZERO collaborations at the Fermilab Tevatron, or the ATLAS and CMS collaborations at the CERN Large Hadron Collider, are endowed with complex, state-of-the-art, outstandingly designed, and precisely crafted systems which are generically called "triggers". Without the perfect operation of their triggering systems, those beautiful experiments would be like behind-the-back-handcuffed jugglers, utterly unable to make any meaningful use of their ultra-sophisticated capabilities.

(Above, a view of the CMS detector during assembly).
I wish to explain why hadron collider experiments needs a trigger system today, and in so doing I will have to also digress into an explanation of a few ancillary topics. Let me start with telling you what really happens when two hadrons collide.
Hadron collisions are boring -well, most of them are!
Even if through years of R&D and design of a powerful accelerator you have made sure that the energy of your protons is the highest ever achieved, when you launch them one against the other you are still by no means likely to produce a very energetic collision; let alone producing interesting, massive new particles! In fact, it takes a lucky chance for a constituent in the proton to carry a large fraction of the total energy of its parent, and the real collision is between constituents, not between the two protons as a whole.
 Protons are like bags of junk, and they are capable of flying one through the other without much happening. The quarks and gluons they contain are "hard" objects instead: it occasionally happens that a tin can inside one bag comes in a collision course with a bottle of gin contained in the other bag, and then -only then- an interesting collision takes place. Glass bits will fly away in specific directions, and we will learn something about the brands that the owner of the bag likes to drink.
Protons are like bags of junk, and they are capable of flying one through the other without much happening. The quarks and gluons they contain are "hard" objects instead: it occasionally happens that a tin can inside one bag comes in a collision course with a bottle of gin contained in the other bag, and then -only then- an interesting collision takes place. Glass bits will fly away in specific directions, and we will learn something about the brands that the owner of the bag likes to drink.Now, as much as I like the above example with bags of rubbish, let me leave it alone. I need to explain that even in the rare cases when the interaction between proton constituents that we manage to originate is indeed energetic, usually nothing much interesting happens. This is because the most likely interaction occurring between one of the quarks and gluons that bind together inside a proton and its counterpart in the other proton is one governed by Quantum Chromodynamics, QCD for insiders. And QCD is not something we need to study in any more detail than we have in the last thirty years!
Indeed, no: the Large Hadron Collider has not been built to increase our knowledge of QCD-mediated processes, despite the fact that it will nevertheless do so, to a very significant degree. the LHC, with the experiments sitting in its underground caverns, has been built to study the origin of electroweak symmetry breaking, and search for new physics beyond the standard model.
Now, electroweak processes are exceedingly rare as compared to QCD processes, when we take protons as the projectiles: for instance, only one collision in a million involves the exchange of an electroweak boson; and to produce one single Higgs boson, the particle which will finally explain many of our unanswered questions on subatomic physics, we need to collide ten billion proton pairs, or more.
A reference candle: the Higgs
The rarity of the processes we are interested in studying poses an enormous problem to the design of a hadron collider experiment. Let us take as a benchmark the goal of collecting a thousand Higgs boson events in the very clean "four-muon" final state: such a sample (together with the others that are concurrently gathered) is sufficiently large to yield answers to some critical questions about the nature of the Higgs field and electroweak symmetry breaking.

Unfortunately, if we want to collect a thousand "clean" Higgs boson decays we need to produce many more: this is because of several facts. First of all, the detector efficiency for correctly measuring all the final states from the decay is not 100%.
A H -> ZZ -> 4 muon decay will produce four energetic muons, and if our detector is 90% hermetic to each muon from such decays, a 4-muon event will be seen as such only 0.9^4=65% of the times. But more importantly, the multitude of possible decays of the Higgs makes the four-muon final state a rarity: the H decays to a pair of Z bosons only twice every ten times, in the most favourable circumstances; and the Z boson decays to a pair of muons only 3.3% of the times... All in all, only 0.65 x 0.2 x 0.033 x 0.033, or about 0.0001 Higgs decays produce four well-identified muons in our detector. So we need to produce ten million of them to get a thousand!
A hundred thousand trillion collisions
Now, given the above mentioned rarity (the one-in-ten-billion chance) of Higgs production processes, ten million Higgs events require us to produce a hundred-thousand trillions of collisions - a number which is better written as 10^17. How to picture 10^17 in a way we can grasp ? If you have that many dollars, you can give 20 millions to every human being. If we are talking of sand grains, 10^17 of them are enough to dress up a hundred miles of shoreline.
10^17 collisions are thus quite many. The question is then, how long does it take to collect such a large statistics of collisions in our detector ? This is not the most meaningful way to pose the question - much better is to change the perspective and refer everything to the time we are willing to wait.
So let us start by asking ourself what is an acceptable time we can wait while our detector collects the data. Let me take seven years as a reasonable time span during which we expect to collect the information of the proton collisions. Seven years are about two thousand working days, for a typical accelerator. Machinists are not lazier than postmen or attorneys: but such large machines require periodic shutdowns, servicing, and other down-time activities that reduce the number of good days during which collisions can be produced.
In two thousand working days there are, say, a hundred and seventy million seconds; but even a very efficient collider will not be running at full power continuously, and the same goes for the detector, so I feel justified in taking 100 million seconds as the full operational time of our giant toy, in seven years. If we are to collect 10^17 collisions in a hundred million seconds, we are looking at 10^17/10^8= 10^9, or a billion events per second that need to be acquired, digitized, and stored on mass storage.
A billion events per second ? For crying out loud - Houston, we have a problem! Actually, there are at least two big problems with such a large rate.
The first problem is that the detector takes some time to record the passage of the particles, and even more time to be read out. The physical processes that take place in the detecting elements, allowing crossing particles to be identified, are very fast but not instantaneous; the electronics reading out the output signals of those detecting elements also takes its time. We are not capable of acquiring data at the rate we are talking about here, i.e. one event per nanosecond. Not in all of the detector subsystems: some of them are less fast than others.
 The second problem, and the most grievious one, is that today's detectors produce of the order of a megabyte of raw data every time you read it out, and with today's or tomorrow's technology, storing on the fly a billion megabytes per second, that is a thousand Terabytes per second, is a non-manageable task.
The second problem, and the most grievious one, is that today's detectors produce of the order of a megabyte of raw data every time you read it out, and with today's or tomorrow's technology, storing on the fly a billion megabytes per second, that is a thousand Terabytes per second, is a non-manageable task.Does the above mean that the whole endeavour is useless ? No: remember, I said it at the beginning: most of the collisions are not interesting. We may throw them away, if we are capable of selecting and storing the really golden ones. There is a concordance between the fact that we do not need to store all events and the fact that we cannot do it!
So, despite approximations and the fact that I am hiding from your view the added complication of the possibility of collecting and storing multiple events in a single detector readout -something which may "ease" the problem by up to a factor of a 100- this is, in a nutshell, why hadron collider experiments need a trigger system.
So, the Trigger...
A trigger is a online selection system which takes care of reading out the fastest components of the detector, and deciding on the fly with that partial imformation whether the event is interesting enough to be stored to disk, or deleted forever. It is a critical device! What we discard during data-taking will never make it into our analyses. So the selection needs to be very wise.
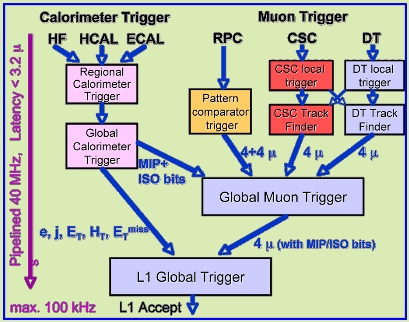
(Above, a block diagram of the CMS L1 trigger).
Triggers usually make heavy use of a parallelized design, exploiting the symmetry of the detector: the same operation may be performed at the same time on different parts of the detector. Yet on a global scale they are essentially serial devices: in fact, they are usually divided in "levels". At CMS, there are only two such levels, but in all other collider experiments there are three. The idea is that each level selects the data that becomes an input for the following, which has more time available and more information to take a better decision.

In CMS the first level trigger uses a readout of very specific, fast components of the detector, and tries to sort out the most energetic collisions, and those that are likely to contain interesting objects, such as electron or muon candidates (particles of high value in hadronic collisions, because they only originate from electroweak interactions!). The decision is made in a very short time -of the order of a microsecond or so- with custom-made electronic components, and it is usually a "NAY!". That is, the first-level trigger usually rejects 9999 events in ten thousand!
By cutting the input rate by a factor of 10,000, the first-level trigger allows the second-level trigger of CMS to breathe. At the LHC, the collision rate is not a billion per second as I calculated above in back-of-the-envelope style, but rather 40 million per second. The reason is that at full power a single interaction between a "bunch" of protons orbiting in one direction and the opposite one coming toward it will on average yield 25 proton-proton collisions! That is, by having very dense proton bunches, we increase the number of collisions occurring simultaneously. An "event" is thus the combined result of those 25 hard interactions -it will be the task of the analysis experts to sort them out offline.

Now, what was an input rate of 40 million events per second, becomes a rate of four thousand (mind you, I am quoting numbers rather liberally here -I am not even bothering to check the real figures in the CMS technical design report. I do it on purpose: what I would like you to grasp is the essence of the idea, and not the details of the implementation).
Four thousand events per second ? This is quite manageable! In 250 microseconds the whole detector may be read out with care, the information processed in fast computer systems, and a well-informed decision can be taken on whether the event does contain electrons, or muons, or suspiciously large missing energy (a hint of the production of neutrinos, or dark matter particles!), or possible new massive particles produced and exploded in very energetic jets of hadrons.
The devices performing this final decision at CMS are called "High-Level Triggers". Note the plural: this is a collection of software programs optimized for speed, each of them scanning the detector information in search for a signal of one, or two, interesting objects -electrons, or muons, or jets, or missing energy, or photons, or tau candidates. Each trigger takes its own decision, and in the case this is a "Yes", the event is sent to an appropriate output stream.
The details of how the storage is handled is beyond the scope of this far too long article, and I will not discuss it here. What is interesting is that of the forty million collisions occurring per second in the core of the detector, only two or three hundred are stored for later analysis!
So in the end, what CMS does -as ATLAS, and the other experiments operating at hadron colliders- is to restrict its search to a very narrow subset of the original bounty of collisions. If the trigger system has done its work well, those few survivors will tell us what we want to know. If the trigger, however, allowed interesting events of some exotic kind to seep through its mesh, and be lost forever, we would be in trouble!
We are very confident that no interesting physical processes get lost down the drain. Yet despite our self-confidence, we have set "parachute triggers" in place, that collect events without applying any selection. That is, these triggers do select events, but they do so blindly: one event every million or so gets recorded regardless of its features. By studying those "unbiased" events which passed thanks to a random choice, we get confident that we did not lose anything interesting!
Conclusions
I hope this long post has been less selective than the CMS trigger: of ten thousand readers that will load it in the next few weeks, maybe a thousand will make it through the first page, and maybe a hundred through the first half. I would be happy if ten readers were interested enough in the topic to read through to this conclusions section: if you did so, you belong to the very selected few who justified the writing of the whole piece, as the few events that get selected every second by the CMS trigger justify the whole multi-billion-dollar project!


Comments