

Integrated luminosity is a measure of the amount of interactions produced by a collider. For protons ran against proton, one inverse femtobarn corresponds to roughly 80 trillion collisions. Of these, the detectors can only store a small part due to data acquisition bottlenecks, but this is not a problem - most of the interactions are absolutely of no scientific value. The majority of them in fact release very little energy: either the protons "slide" elastically one on the other without even disgregating, or they actually compenetrate and traverse one another without much happening.
Physicists are rather interested in the small subset of very energetic collisions whereby a quark or a gluon in one proton hits a quark or a gluon in the other proton "heads on", releasing a large fraction of the total kinetic energy of the system in a form which can then materialize new particles. So the collider experiments are equipped with sophisticated "triggering" systems which can recognize the energetic collisions in a number of ways, flagging the event as worth collecting and enabling the writeout on disk of the corresponding large amount of data produced by the various detector components.
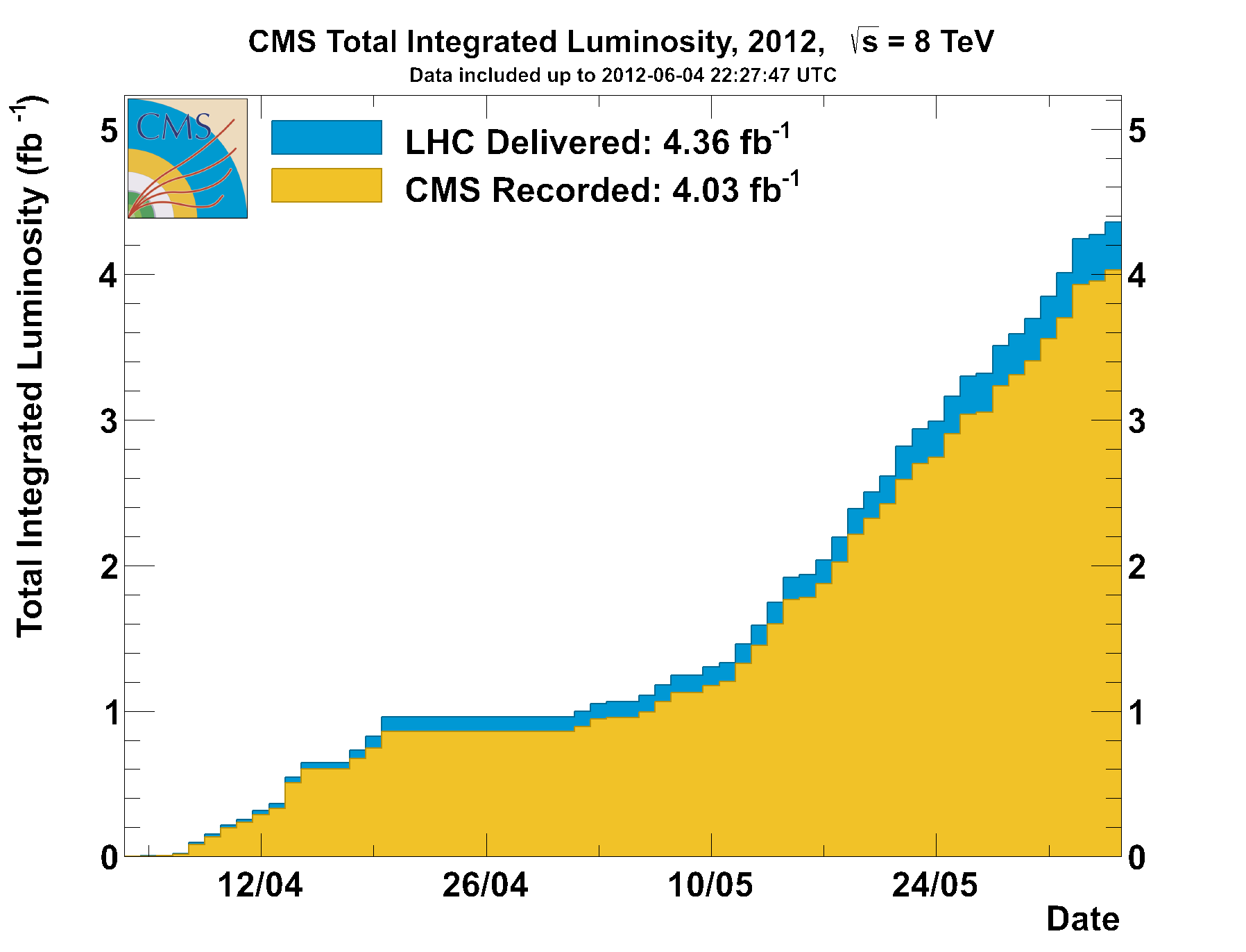
Four inverse femtobarns therefore do not correspond to 320 trillion events to analyze, but luckily to a lot less than that. Here, however, we should be concerned with what we could find in those data. And one thing we might find is additional evidence of Higgs boson decays. As you probably well know, last December the CMS and ATLAS collaboration released preliminary results of their Higgs boson searches (final results have been then published a few months ago). Those results were based on the analysis of data corresponding to the five inverse femtobarns of integrated luminosity collected in 2011 from 7 TeV collisions.
Because the higher the total energy and the higher is the expected production rate of rare particles such as the Higgs boson, the slightly higher centre-of-mass energy of 2012 running makes the data collected until today roughly equivalent in discovery reach for a Higgs boson as the 2011 data. Since the two collaborations together found in 2011 a tentative Higgs boson signal at 124-126 GeV with a local significance of roughly four standard deviations, it is very likely that, if that signal is real, the 2012 data contains a signal of similar statistical power. Note that the new data has been blinded by the experiments: we do not know what is in there, but we will soon !
Now, forgive me for the oversimplification, but if one naively added in quadrature two four-sigma effects, one would obtain a over-five-sigma combined significance: this would then be a discovery by all standards. In principle, therefore, the chance that the Higgs boson is found is already there, with data already safely stored on our multi-tiered storage systems.
I may perhaps be forgiven for my simplified statement by looking at the graph below, which describes the significance level of a Higgs boson in LHC data as a function of the particle mass.
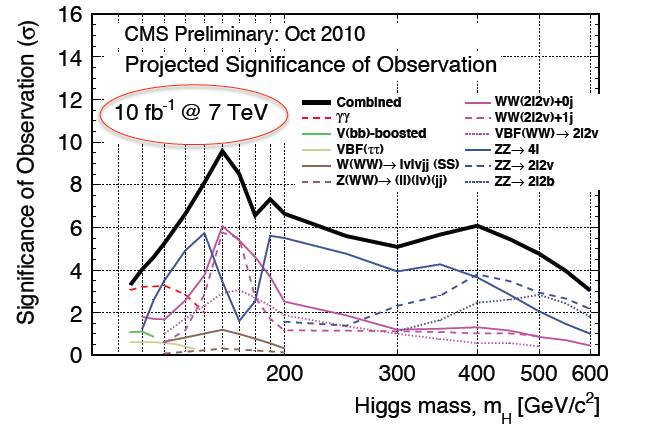
As you can see, for a 125 GeV Higgs boson the combined significance of CMS searches with a 10/fb dataset at 7 TeV collisions (which I have explained above is roughly equivalent to what is already in store by adding the 2011 and 2012 datasets) is just short of five standard deviations. But this is one single experiment ! ATLAS is just about as sensitive as CMS, so the two experiments together certainly have enough sensitivity to grant a >50% chance of a Higgs boson discovery by now, if the particle is there.
Now, of course in the discussion I have been significantly simplifying things for the sake of argument. In reality, one should take into account several factors that may affect the sensitivity of the 2012 datasets; among these are the higher "pileup" of the new data: the higher rate of data collection this year comes from having more protons in the beams, and this causes the interesting "Higgs production" collision to come accompanied by two dozen additional collisions which have nothing to do with it, and whose general effect is to make it harder the reconstruction of the final state particles.
One specific example of the smearing that the pileup causes is in the case of the Higgs decay to photon pairs: in order to reconstruct with precision the invariant mass of the hypothetical Higgs boson in a event containing two photons, experimenters need to make a hypothesis for the exact location on the beam axis of the proton-proton collision producing the Higgs, and this is hard if the Higgs only decays to two photons, because photons do not leave tracks in the detector! The location of the vertex is flagged by the amount of other softer particles that are produced by the protons disgregation when the Higgs boson is created, but if there are twenty such collisions together it becomes hard to correctly pick the right vertex. The occasional mistake leads to a "smeared" mass distribution, which is less peaked and thus stands out less on the large backgrounds. This problem is solved by refining algorithms and smarter analyses, but I hope I have given you an idea of why every run is different, and why the above argument about the new data roughly corresponding to the old data is a handwaving one.



Comments