



We often teach each other by describing procedures, but these descriptions take much for granted. This, I think, was the point of the peanut butter exercise. And this, it turns out, is the key insight responsible for the recent boom in the field of artificial intelligence. Procedures, rules, guidelines, routines: these are really high-level abstractions, masquerading as fundamental units of intelligence. “Spread the peanut butter” is less an instruction than a vague suggestion, unpacked and filtered through a vast network of experienced spreads, nuts, butters, breads, knives, jars, and muscle twitches contained in the collective memory of 100 billion interconnected neurons in the human brain, the refined product of a million years of ancestral successes and failures in tasks not dissimilar from buttering bread.
Last week, Suman and Mary arrived at my 9 a.m. office hours with their laptops. Suman was looking particularly haggard, resting his head in his arms while Mary explained. They had been up all night working on the last problem of a programming assignment on search algorithms in the undergraduate AI class, for which I am a graduate student instructor. Specifically, they were trying to devise a strategy for Pacman to find the most efficient route through a large maze, eating all the food dots. Exact solutions take too long to compute, so the three teams with the best scores get extra credit.

Suman and Mary really wanted those points. They had some good intuition about what makes for an efficient route: Don’t stop midway through a tunnel; Go for dead ends first; Split the board into regions and finish a region before moving on. But as the night wore on, they began to appreciate the difficulty of translating these ideas into an algorithm for Pacman. How exactly should Pacman go for dead ends? Before what? Strictly preferring the closest dead end is too literal, a bit like wiping peanut butter on a loaf of bread. This is when rules get complicated. Pacman should head for the closest dead end, but only if there are food dots on the way. Or if he knows he’ll have to come back through the same region, the nearest dead end can wait.
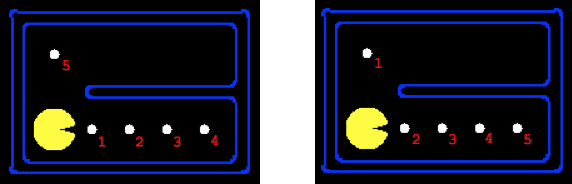
Consider a different approach to the Pacman route problem. Start by creating a “greedy” route. That is, Pacman eats the closest remaining dot until the board is empty (are you convinced that’s not optimal?) Think of this route as an ordered dot-eating: Pacman eats dot 1 then dot 2, and so on, with a total step cost that’s the sum of the distances between each pair in the ordering. We’d like to improve on this ordering by making incremental changes. Here’s the key idea. It’s called 2-opt. Grab two segments in the current ordering and reconnect them in the other possible way, if doing so results in a route with a smaller total step cost. Repeat this move until no more improvements are possible. In the example below, the greedy ordering on the left has a total cost of 10 since Pacman has to retrace his steps along the bottom. A single application of 2-opt results in the optimal ordering on the right with a cost of 8, as it’s more efficient to eat the dot that’s two steps away first.
This is quite different from encoding rules. Unlike the intuition that Suman and Mary articulated in English, this method is easily understood by a Pacman. In fact, it is the basis for the Lin-Kernighan algorithm which is often used for solving very large routing problems. Indeed, Pacman search is really an example of the famous Traveling Salesman Problem, which comes up in UPS delivery planning and computer chip layout. Remarkably, Lin-Kernighan can find a solution that comes within 1% of the best possible solution for million-dot Pacman search in less than a minute.
Recent progress in AI is due to a paradigm shift in thinking, which can be summed up as: Pacman is not human. Obvious, perhaps, but subtle in implication. What’s so special about 2-opt? It casts Pacman’s debacle in mathematical terms (minimize the sum of a bunch of distances), and provides a method for performing the minimization (flip two pairs of connected dots). In a sense, this is just calculus: describing functions and finding extreme points. But when it comes to creating intelligent behavior from scratch, we’re biased by the way we experience our own intelligence, which is typically procedural. Learning to think mathematically about things that we have learned do without really noticing is very hard.
To make matters worse, computer programming is nothing if not procedural. Computers require explicit instructions in special languages that limit vagueness, and precisely specifying conditions and actions, as we learned from Mr. Davids, requires some practice. That’s why programming feels so foreign to students accustomed to writing five-paragraph essays. In contrast, the ambiguity of human language makes it powerful: our ability to fill in enormous contextual gaps allows for succinct communication. It wouldn’t take long to describe the production of a peanut butter sandwich to the ordinary human version of Mr. Davids.
Lin and Kernighan were working on local search for traveling salesmen over 40 years ago. Still, much of the AI research conducted in the ‘70s and ‘80s involved cataloging rules and procedures into “knowledge bases”. Engineers hoping to automate speech recognition agonized over adapting linguistic knowledge into computer code; the same thing happened with machine translation. But these fields only took off in the ‘90s, when researchers largely abandoned linguistics, and built simple statistical models of the training data. A transcription is simply the sequence of words with the highest probability according to the model; same with a translation. The models are overly simple, and recent work shows some hope for harnessing ideas from linguistics, but to get off the ground, we had to stop thinking about how humans act intelligently and start from scratch.
Eventually, Suman and Mary came up with an elegant way to find efficient Pacman paths. While their set of rules had grown to over 300 lines of code, the new method took only 10. Their solution is a bit beyond the scope of this article: A* search with a cleverly designed inadmissible heuristic. While the greedy path has length 350, their method took Pacman down a path of length 286, good enough for 3rd place. The winning path had length 280, and used an idea much like 2-opt to improve the greedy path step by step.
Meanwhile, I thought about Mr. Davids covered in peanut butter, and wondered if, despite talking in procedures, our brains might actually be learning by maximizing functions.



