

New advances in DNA sequencing technology have been receiving a lot of press, but mostly in the context of how DNA sequencing is going to make personalized medicine possible. Your physician will some day be able to prescribe drugs and give you advice on disease prevention, all based on a reading of your DNA. Obviously that day is not here quite yet; however, the amazing power of next-generation DNA sequencing is already transforming what goes on in a biology lab.
To see this, we can take a look at an old technology and look at the changes it has gone through, from its pre-genome-era state in the 80's and 90's, to its transformation into a genome-scale tool around the turn of the millennium, to its latest incarnation during this emerging era of massive, cheap DNA sequencing. This technology, called chromatin immunoprecipitation (or ChIP), has been a critical tool in studies of how genes are regulated. ChIP, in its current, next-generation DNA sequencing form, is opening up some stunning new approaches to studying gene regulation.
Switching genes on and off
To understand how this technology has changed, we need to begin by understanding what kinds of research questions we can address with ChIP. One way that a cell controls what is going on inside itself is by switching genes on or off. (Keep in mind that genes don't always exist in just one of two states - there are states in between fully on and fully off, but we can ignore that here.) Genes are switched on or off when a protein called a transcription factor binds to a stretch of DNA. From that vantage point, sitting on the DNA, the transcription factor can direct what happens next: gene expression machinery gets recruited to the DNA, and the gene is turned on, or a set of repressing proteins is brought to the DNA instead, and the gene stays off.
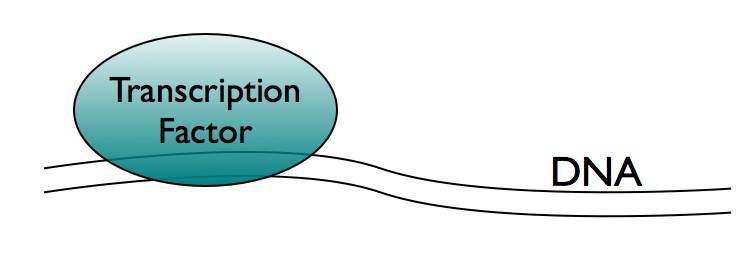
This method of control - controlling genes by transcription factor proteins - is critical for much of what goes on inside a cell. It is important during the process of development, as a single-cell zygote turns into a fully grown organism. Transcription factor controls enable cells to properly respond to stress, to adapt to different nutrient environments, and they often go awry in cancer. It should be no surprise then that transcription factors have been a hot area of study.
Often we have a transcription factor, and we want to know what genes it controls. One way of finding out is to discover what stretches of DNA a transcription factor binds. If a transcription factor grabs on to a stretch of DNA, that's a good (but not definitive) clue that the transcription factor regulates a nearby gene. But how can we figure out where a transcription factor binds?
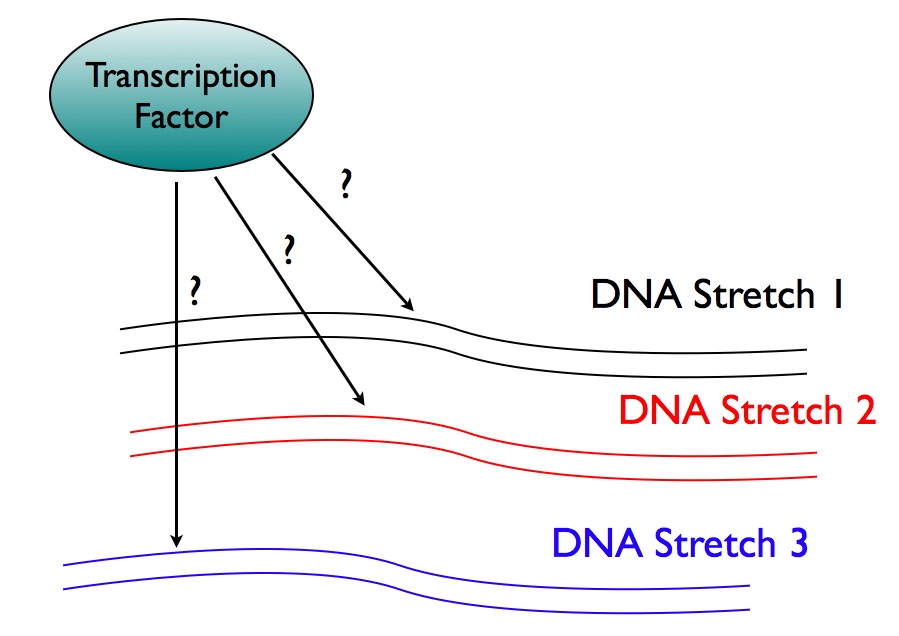
How we do ChIP
This is where ChIP comes in. ChIP lets us pull out that little stretch of DNA that's bound by the transcription factor. With that stretch of DNA in hand, we can then make an attempt to characterize it. Here is how ChIP works:
1. The transcription factor binds a stretch of DNA.
2. An antibody, made especially for this purpose, grabs hold of our transcription factor of interest.
3. The antibody comes pre-attached to a gigantic bead - the only thing in this whole experiment large enough to see with the naked eye. We can pull down the bead, which pulls out the antibody, which pulls out our transcription factor of interest, which comes down with the DNA it is bound to.
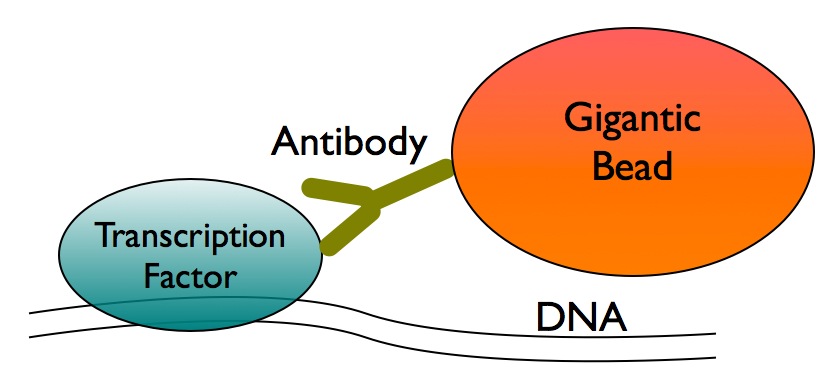
Basically, you pull down a bead, and everything else that you want comes down with it. Once you've got what you want in a test tube, you throw away the bead, antibody, and transcription factor; what you're left with is the DNA. And the issue now is to figure out just what that stretch of DNA is.
What is that stretch of DNA? ChIP-PCR
In reality, you haven't just pulled down one stretch of DNA, you've pulled down dozens, or hundreds. That is because transcription factors don't just bind one stretch of DNA: they usually regulate dozens or hundreds of different genes, so they bind to dozens or hundreds of different DNA stretches. By doing ChIP, we have now separated those dozens or hundreds of genes from the thousands in the genome that were not bound by our favorite transcription factor. We've narrowed down the possibilities, but we still don't actually know what we have in our test tube. In fact, at this point, we all we have is a tiny clear drop of liquid inside of a test tube, full of molecules so small that not even a microscope will help us identify them. We need to turn to other technological options.
The oldest option, all that was available in the pre-genome era, is based on a guess. You have to guess, "I think my favorite transcription factor binds gene Y." You can guess that your transcription factor bound gene Y, which would mean that gene Y should be in the little drop of clear liquid in your test tube. And you can then test for gene Y using the Polymerase Chain Reaction (PCR), which will tell you whether gene Y came down in your ChIP experiment. (This technique is called, obviously, ChIP-PCR.)
If your guess is right, that's wonderful, but you still just know about one gene that is bound by your favorite transcription factor. You can keep making guesses, and do more PCR reactions, but ultimately you're bound to miss something. Hopefully your guesses are educated ones, because if you have no idea, then there is simply no way that guessing randomly will work. You cannot test all of the thousands of genes in a genome by PCR.
What is that stretch of DNA? ChIP-chip
The problem should be clear now: we've done a ChIP experiment with our favorite transcription factor, and we have a tube with a small, clear drop of liquid containing possibly hundreds of different genes, but we have no idea what those genes are. We can't just go down the entire list of genes for an organism, testing them by PCR, because it is prohibitively resource intensive, and before we had genome sequences, we didn't have that entire list of genes anyway.
But genome sequencing changed it all. With genome sequences available, scientists could construct DNA chips, little slides that contained probes for every single gene in a genome. Instead of testing genes one by one with PCR, you could take your DNA pieces and stick them on to the DNA chip, and test them all at once. It works like this: the DNA chip has probes for every single gene in a genome. If you have a sample containing DNA from a particular gene, that DNA will stick to the corresponding probe on the DNA chip. To actually see the DNA that has stuck to a particular probe, we label the DNA with a fluorescent chemical. Thus, if a probe is lit up, you know you had DNA for that gene in your sample:

So now instead of ChIP-PCR, we can do what's called ChIP-chip (first performed on yeast proteins and reported in this ground-breaking paper): you can take that small drop of clear liquid, and find out exactly which genes were pulled down by your favorite transcription factor when you did ChIP. We can identify all of the genes bound by the transcription factor: we no longer have to guess.
But there are limitations. The results from the DNA chip can be noisy, so some faint signals may get lost in the background. DNA chip is also not always as precise as scientists would like: sometimes we want to know exactly where on the DNA our transcription factor was sitting, not just which gene it was near. It can be hard to do this with ChIP-chip. And perhaps the most important limitation is that you have to actually build the physical DNA chip, which is expensive and time consuming.
Building these DNA chips can be a real drag when you want to do cross-species comparisons. What if you want to test ideas about how gene regulation has evolved? Maybe you want to know whether your transcription factor binds the same genes in mice, rats, humans, dogs, chimps, macaques, and the platypus. We have sequenced the genomes of all these critters, so we could make DNA chips if we wanted to, but remember, it is expensive and time consuming. This is where next-generation DNA sequencing comes in: you no longer need the DNA chip.
What is that stretch of DNA? ChIP-seq
With the latest DNA sequencing technology, you can dispense with building a DNA chip. You no longer need to make probes, put fluorescent chemicals on your DNA, and see which probes your DNA sample sticks to. Instead, you just take your DNA sample sequence it - you can now find out directly just exactly what DNA is in that small, clear drop of liquid.
It works like this: once you have done ChIP, you have a tube with a small, clear drop of liquid containing thousands of little pieces of DNA. When you put that whole sample on a DNA-sequencing machine, each little piece of DNA in your sample will generate what are called sequence reads - readouts of the actual DNA base sequence (such as 'GGTCATGCTGATTGCTTTGAA'). The computer hooked up to the sequencing machine spits out millions of these little sequence reads from one sequencing experiment; the next step is to line them up against the sequence of the known genome. In most places around the genome, few if any of your sequencing reads will match up: that is because when you did ChIP, you separated a few dozen or a few hundred genes from all of the rest of the genome. So your sequencing reads will correspond only to those parts of the genome that ended up in your sample, that is, those genes bound by your favorite transcription factor. You will find instances where 20 or 50 or 100 different sequencing reads will all match to the same spot in the genome, right next to gene Y, indicating that gene Y is bound by your favorite transcription factor. In other words, whenever there is a stretch in the genome corresponds to piles and piles of your sequencing reads (and they are piles - remember, you get millions of reads in these experiments), that is where your transcription factor bound.
You can easily use this technique, called ChIP-seq, to test your transcription factor in different species, different mutant versions, different disease states - all much easier than you can with ChIP-chip. ChIP-seq also tends to be less noisy, and often gives you better resolution than ChIP-chip.
This is one way that scientists can answer important questions about how genes are controlled. The original technique of ChIP has undergone some major upgrades as genome sequences, DNA chips, and now high volume, low cost sequencing all became available. These transformations of the technology have allowed scientists to answer new questions upon each iteration, questions that were hopelessly out of reach just 15 years ago. These changes in technology may not have yet transformed what goes on in your physician's office, but they have changed how we do science, and ultimately we all hope that progress in biomedical science will result in better health.


Comments