


So-called AI is enjoying a similar frenzy. Though they are still just Large Language Models (LLMs), and the best analogy for that is a fancy autocomplete, they are attracting huge levels of financial investment partly because of the potential and then primarily because people want to make money on stocks, not companies.
The Dot-Com Bubble did collapse but progress continued without the hype(1) you can buy dog food affordably on the the internet now, though the big money is artisanal dog food marketed toward wealthy elites. That may be the future for AI in 25 years also. For now, while AI is still a long way off, tasks that academics considered challenging for LLMs, like the 2020 Multitask Language Understanding (MMLU) benchmark designed to evaluate ability using 57 topics, are now easy for the private sector to master.
So academics are trying again, this time with Humanity’s Last Exam - a 2,500‑question evaluation-tool that covers math, humanities topics, science, ancient languages and various subfields. But will making the test bigger be anything more than a bump in the road for tools that exceed at taking tests?
The authors of the new test think it can, because they believe they have gone beyond pattern recognition and instead demand both expert knowledge and understanding context. Context is generally where LLMs fall apart. Making an imagery LLM with code that says 'don't create humans with six fingers' does not solve the problem; LLMs don't know what fingers are and love to create humans with six of them unless you code around it.
Being good at taking tests is not "intelligence" so will a harder test be better at figuring out where LLMs are compared to humans? The questions are all arcana by people who were tasked with creating obscure questions. Some of them are just subjective so there isn't a right answer. Others, like Biblical Hebrew pronunciation or translating Sumerian, wouldn't seem to be close to AI at all, they are just obscure challenges. Gemini 3.1 Pro and Claude Opus 4.6 can be 40 percent accurate while the regular free stuff can perhaps achieve eight percent.
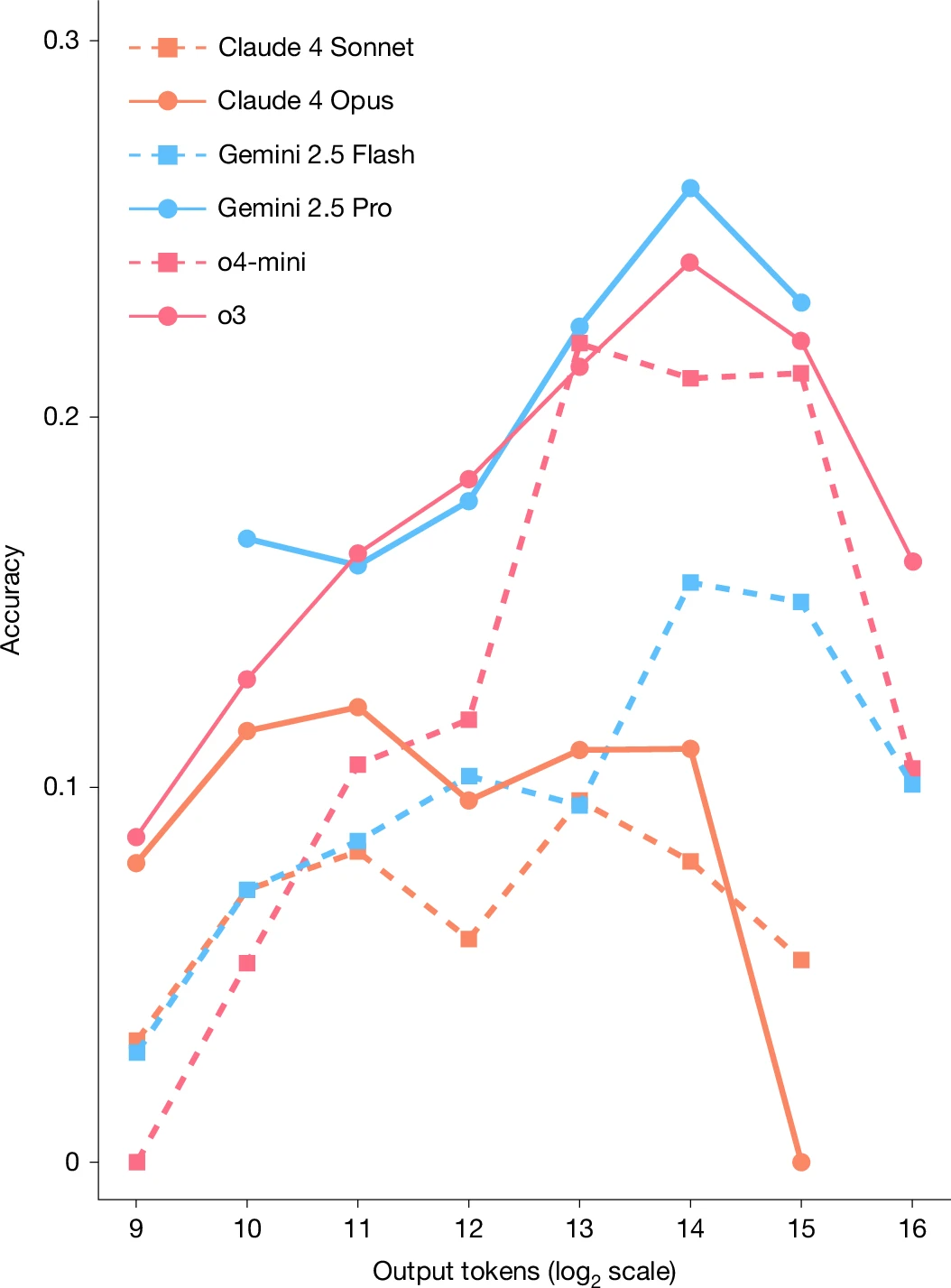
The name, Humanity's Last Exam, sounds definitive, but the last word on Artificial Intelligence has not been written and it will almost certainly not be inscribed by 1,000 academics creating harder questions. It is still a test and those do not measure intelligence.
Citation: Center for AI Safety., Scale AI.&HLE Contributors Consortium. A benchmark of expert-level academic questions to assess AI capabilities. Nature 649, 1139–1146 (2026). https://www.nature.com/articles/s41586-025-09962-4
NOTE:
(1) Science 2.0 began to gestate in my head because I heard Tim O'Reilly talk about the "Web 2.0" that would be created from the ashes of the Dot-Com collapse and it followed to me that if commerce could be reshaped, so could the collaboration, communication, participation and publication of science.
I did not see that social media would create a race toward the bottom, even among scientists.




Comments