



Anyone who has used news feeds or Twitter/Facebook knows that the torrent of updates quickly becomes saturated with noise and is impossible to manage. What we need are information aggregation services that can automatically customize filters for our personal interests. For example, I might generally prefer to receive updates from certain "good" friends on Facebook, but couldn't care less about the numerous mundane updates from my other "friends." But I also might want to know that an old acquaintance from high school is having a baby, or that my second cousin has posted a bootlegged sneak preview of an upcoming Star Trek movie. A useful aggregation service should be able to automatically learn to surface only results that are interesting (to me) and suppress the uninteresting majority, despite collecting from hundreds or thousands of data sources.
Imagine a world where all computer programs can automatically learn to adapt and customize to our personal information needs. We all want to make informed decisions about how to spend our time and money, but there are simply too many options or too much information for us to efficiently process.
The tools to help us deal with this information overload are called information retrieval and recommendation systems. Information retrieval tasks can be categorized into a sliding scale between two extremes. At one end, we have passive browsing, which typically starts at news or aggregation services such as customized blog feeds, news sites, Digg, Twitter, and Facebook. At the other end, we have keyword search such as via Google, which is driven by specific information needs. Filling out the middle are various recommendation scenarios covering the whole range of passive to active user intents (e.g., targeted banner ads on the NY Times, or product recommendations on Amazon). As we become ever more dependent on the internet, we are faced with a two-pronged problem: an increasing variety of retrieval tasks coupled with digital content that is growing at an alarming rate.
Current techniques for designing retrieval systems cannot scale with growing demand. While most existing systems are highly flexible and can be reconfigured in a number of ways (many of which might be good fits for new retrieval domains and tasks), finding the best configuration is still a labor intensive process that requires substantial hands-on human expertise.
The key observation is that information retrieval systems do not exist in a vacuum; they must interact with users. The information we search for, the web pages we browse, the emails we send, the Twitter tweets we post, the items we purchase on Amazon -- they all leave digital footprints that reflect the fine grained dynamics of our online activities. These interactions are plentiful and can be harvested at virtually no cost. As such, one can easily imagine developing systems that can adaptively reconfigure themselves in new environments by learning from user interactions.
The idea of designing self-improving systems has long been a topic of great interest in the artificial intelligence and machine learning communities. The basic premise is simple: a software application that learns to reconfigure or adapt itself to new or changing inputs (e.g., discovering the best results for search engine queries). The current state of technology presents a tremendous opportunity. Not only can we make exciting new progress in this area, but such progress can also substantially impact the foreseeable technologies of the future. By developing automatic and adaptive algorithms, we might soon see an explosion of new applications that drastically improve the efficiency with which we make informed decisions in every phase of our lives.
In this rapidly growing research area, two technical challenges emerge to the foreground. First, we must accurately interpret user interactions; this is a challenging problem even for humans. Second, since we typically only receive feedback for a limited number of results (e.g., the top 10 results returned by a search engine), we must also actively explore alternatives to present to users, so that we can observe their interactions with the alternatives. Otherwise we might never discover the best configurations for that particular retrieval domain. Furthermore, solutions to these challenges must be prescriptive and precise, so that they can be programmed to run automatically.
Proper Interpretation of User Interactions
Before we can properly design programs that adapt to user feedback, we must first derive useful feedback from user interactions. Although data is plentiful, it remains a challenge to understand what can be learned from observed user behavior.Clicks, What Are You Good For?
Clicks (e.g., on search results) are the most plentiful form of user interactions. But what can we really interpret from them? The biggest known issue is called the position bias effect, where user attention tends to gravitate towards the top few results regardless of usefulness. In a controlled study, Joachims et al. [1] examined search behavior on Google via an eye tracking study.
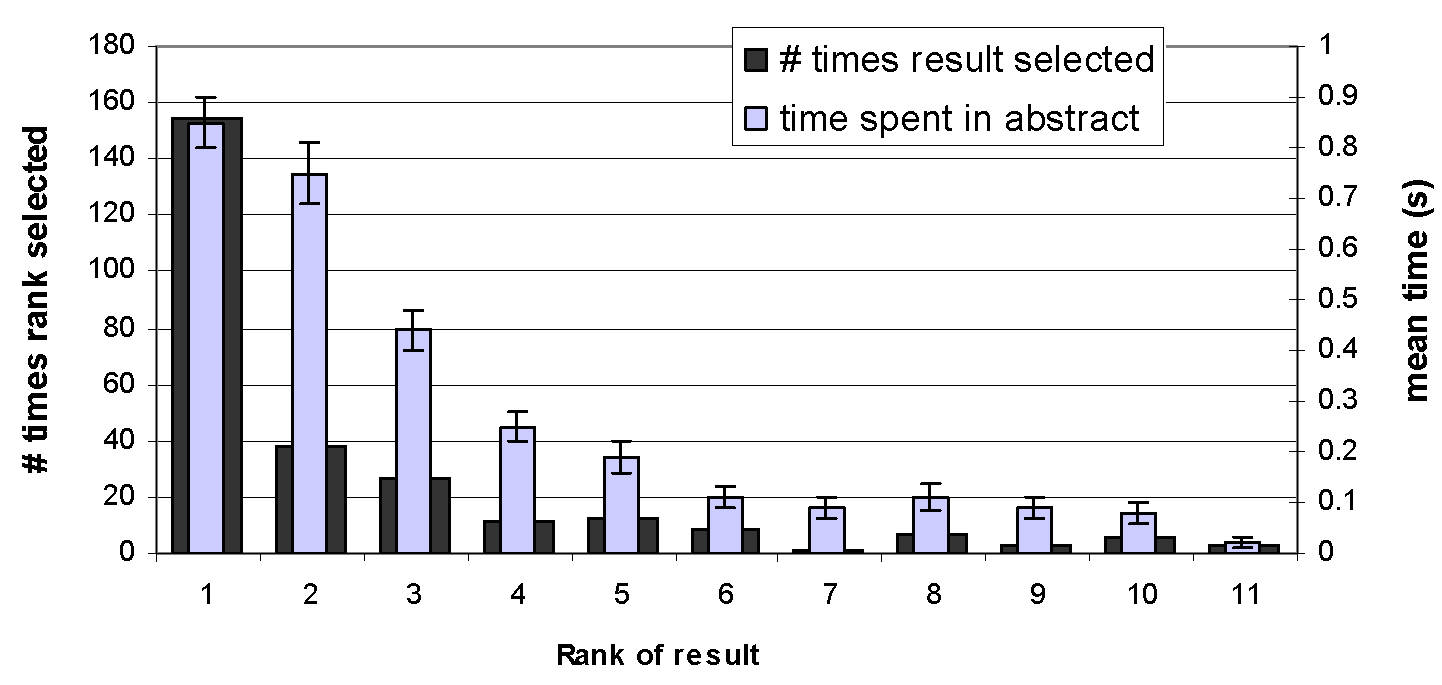
From the figure above (copyright Joachims et al.), we see that not only do users rarely click on lower ranked results, but they often don't even look at them. When the users were presented with reversed rankings (using an http proxy that shuffles the results but preserves the presentation layout of Google), the story remains largely the same. In fact, rather than question the performance of Google, users often lamented at their inability to formulate the proper search keywords.
This leads to a second issue: the vast majority of user interactions provides only implicit feedback. A clicked result need not be a good result. As a simple thought experiment, consider two rankings, where one has good results and the other mediocre results. Which ranking would you expect to receive more clicks? On one hand, all the results in the first ranking are good. But users might click around more in the second ranking due to greater dissatisfaction. Such questions must be resolved in order for computers systems to tease out useful information from observed behavior.
Some Recent Advances
Most studies focus primarily on click behavior in search engines or online advertising, since that is where user interaction data is most readily accessible. But one can easily imagine applying similar approaches to other forms of user interactions and retrieval scenarios.The most straightforward approach is to use only pre-existing interaction logs. Recently, Chapelle&Zhang [2] developed a probabilistic model of dynamic user behavior that uses click logs to simulate users browsing search results. From such simulations, one can make
probabilistic predictions about which clicks indicate user satisfaction (e.g., this clicked result has a 70% chance of satisfying the user, or many users clicked on this result and then immediately backed out so it's probably bad, or this unclicked result had a 80% chance of being examined by the user so it's probably not useful).
Another approach is to gather more explicit feedback from users. The challenge lies in devising informative methods that encourages user participation, as well as in effectively combining this data with the more abundant implicit feedback. Recently, El-Arini et al. [3] developed a blog filtering system that includes simple mechanisms for liking or disliking blog posts.


A screen snippet of their service, Turn Down the Noise in the Blogosphere, is shown above. By providing convenient ways to indicate like or dislike, this system can learn to personalize, as well as reduce redundancy of topics shown. Many other existing services also employ methods for gathering more explicit feedback, such as personalization options on Google and ratings on Amazon and Netflix.
A third approach is to use online experimentation to directly elicit more meaningful implicit feedback. Historically, market researchers have relied heavily on side-by-side or A/B testing methods to measure preferences. Recently, Radlinski et al. [4] showed how to conduct similar experiments for search results by interleaving the rankings produced by two search systems.
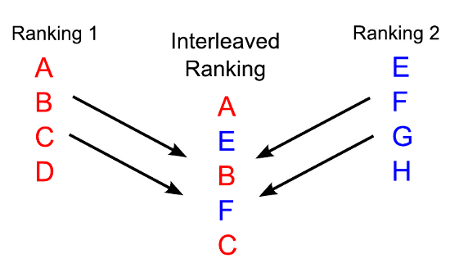
The figure above shows an example scenario. Whenever a user issues a query, we can show the user an interleaving of rankings from two competing systems. This approach deals with position bias by guaranteeing both rankings to have equal contribution at the top of the interleaved ranking. One can then use click counts to measure relative preference. Using the Physics E-Print ArXiv as an experimental testbed, Radlinski et al. showed that interleaving experiments can derive very meaningful implicit feedback. Interleaving approaches can be used to run side-by-side tests at unprecedented scales.
Actively Exploring for the Best Alternatives
Active learning is also crucial for future progress. User interactions are largely limited to the top few options or recommendations. So even with perfect feedback, we might never learnabout superior alternatives if we don't explore new results to try out. The goal then is to design intelligent methods for exploring alternatives (such as which Facebook stories to surface) that incur low cognitive cost and annoyance for the users.
To Explore or not Explore?
One danger to under-exploring comes from rich get richer effects such as information cascades. Most news aggregation sites such as Digg have "top article" rankings. Since users typically only look at the top results, these top articles will then receive increasingly more clicks and ratings so that they become disproportionately popular even if they're not more interesting than many alternatives.The real tragedy arises when results picked up by information cascades are much worse than the best alternatives. Suppose you are a scientist who likes to browse a weekly digest on recently published papers. Of course, certain papers will be more popular (with many disproportionately so). What if that perfect idea to compliment your research happens to be contained in the 50th ranked paper, but you stopped browsing at the 25th and called it a day? Instead of making a connection that would dramatically speed up your own work, it might instead take you extra months or even years.
The challenge lies in understanding the fundamental tradeoff between exploration versus exploitation. It could be that superior alternatives exist. But all the unexplored alternatives could also all be garbage. Should we try to explore more or just make do with what we have? If we over-explore, will that hurt our performance too much?
The theoretical framework used to analyze this type of tradeoff is called the multi-armed bandit problem. In the classical setting, we are given a fixed set of strategies or options without foreknowledge of their value, and must devise an algorithm to automatically pick strategies to play (e.g., choosing which banner ad to show on the NY Times). Our algorithm receives feedback after each step (e.g., whether the banner ad was clicked on). The goal then is to maximize the total payoff (e.g., total number of clicks). This framework is very general and can be applied to almost any setting where we must make a sequence of decisions and only observe feedback on the choices we made.
Some Recent Advances
The widespread applicability of the multi-armed bandit framework beckons for natural extensions that better reflect real world scenarios. There is also a rising need to empirically evaluate proposed algorithmic solutions. Such empirical evaluations can also inform future theoretical work by bringing to light disagreements between known theoretical guarantees and empirical results. This is a wide open and exciting area of machine learning research.The classical bandit setting is extremely simple and assumes all strategies to have fixed expected value and be always available. It also does not consider side information (or context), and defines feedback only as an absolute measure (e.g., between 0 and 1). Not surprisingly, recent theoretical extensions include introducing contextual information (e.g., the best strategy might depend on the query) [5], accounting for the fact that some strategies might be unavailable [6,7], strategies with drifting rewards (e.g., user interests changing over time) [8], and feedback that only describes the relative value between pairs of strategies (e.g., if we used side-by-side interleaving tests) [9,10].
It is now also possible to develop online experimental testbeds. For example, the aforementioned blog filtering service, Turn Down the Noise in the Blogosphere, can support experimentation. Here at Cornell, we have a wonderful collaboration with ArXiv (more information). These collaborations will push the state-of-the-art in machine learning, and also provide valuable services to the general public. And as for the big internet search companies, one can only guess what they're cooking up in order to gain an edge over the competition.
Unfortunately, relatively few research groups currently have direct access to online services to use for evaluation. The easiest thing to acquire are search logs, but it's tricky to use them for evaluation in multi-armed bandit settings. The issue here is that clicks are only logged for results chosen by the pre-existing system. This becomes problematic when evaluating a new algorithm that chooses new results with no click records. Given a large enough dataset, Langford et al. [11] have developed an approach to simulate how different algorithms might perform using pre-existing click logs.
Concluding Remarks
The techniques under development will impact us beyond just progress towards self-improving information retrieval systems. Stated differently, information services can aid us in every aspect of our lives, even those we don't currently view as being information constrained. In reality, many everyday tasks are already automated using computers (e.g., spam detection). But our growing number of systems and services are becoming ever more difficult to maintain and configure. This line of research can provide a layer of more general automation to set the stage for an incredible future to come.References
[1] T. Joachims, L. Granka, Bing Pan, H. Hembrooke, F. Radlinski and G. Gay, Evaluating the Accuracy of Implicit Feedback from Clicks and Query Reformulations in Web Search, ACM Transactions on Information Systems (TOIS), Vol. 25, No. 2 (April), 2007.[2] O. Chapelle and Y. Zhang, A dynamic bayesian network click model for web search ranking, In Proceedings of the 18th International World Wide Web Conference (WWW), 2009.
[3] K. El-Arini, G. Veda, D. Shahaf and C. Guestrin, Turning Down the Noise in the Blogosphere, In Proceedings ACM Conference on Knowledge Discovery and Data Mining (KDD 2009), June 2009.
[4] F. Radlinski, M. Kurup and T. Joachims, How Does Clickthrough Data Reflect Retrieval Quality?, In Proceedings of the ACM Conference on Information and Knowledge Management (CIKM), 2008.
[5] J. Langford and T. Zhang, The Epoch-Greedy Algorithm for Contextual Bandits, In Proceedings of Neural Information Processing Systems (NIPS), 2007.
[6] D. Chakrabarti, R. Kumar, F. Radlinski and E. Upfal, Mortal Multi-Armed Bandits, In Proceedings of Neural Information Processing Systems (NIPS), 2008.
[7] R. Kleinberg, A. Niculescu-Mizil and Y. Sharma, Regret bounds for sleeping experts and bandits, In Proceedings of the Conference on Learning Theory (COLT), 2008.
[8] A. Slivkins and E. Upfal, Adapting to a Changing Environment: the Brownian Restless Bandits, In Proceedings of the Conference on Learning Theory (COLT), 2008.
[9] Y. Yue and T. Joachims, Interactively Optimizing Information Retrieval Systems as a Dueling Bandits Problem, In Proceedings of the International Conference on Machine Learning (ICML), 2009.
[10] Y. Yue, J. Broder, R. Kleinberg and T. Joachims, The K-armed Dueling Bandits Problem, In Proceedings of the Conference on Learning Theory (COLT), 2009.
[11] J. Langford, A. Strehl and J. Wortman, Exploration Scavenging, In Proceedings of the International Conference on Machine Learning (ICML), 2008.


