

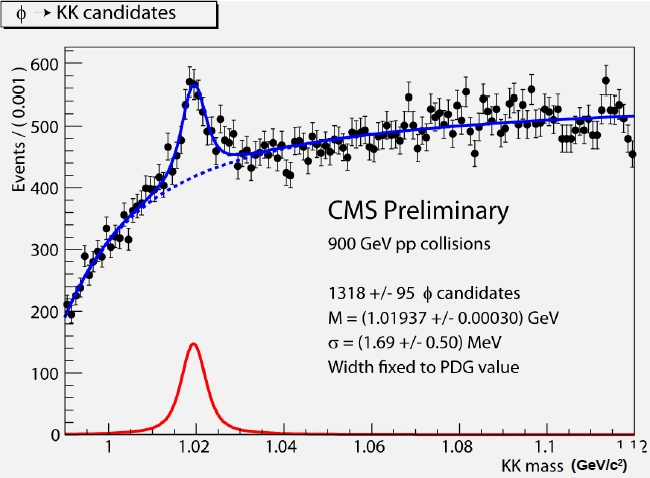
This morning I decided to post here an article describing the details of a new result just approved by the CMS collaboration, the observation of a nice signal of phi meson decays. It is a result of which I am quite proud, and although not really a big deal, it is a nice way to start the new year, while we wait for more data from the LHC.
I had just finished writing the 200-lines piece describing the likelihood fit to the mass distribution, when I decided to save the draft with the "publish" box unmarked, to give it a last reading before submitting it. And the crazy web interface logged me off the site instead!
I optimistically logged in again, thinking that the "autosaving" feature of the web interface must have recorded basically all of the piece. But I was in for a bad surprise: despite Hank's reassuring statements, the thing only remembers the first five lines of text!
So I am on strike today. You are still getting the plot, but I will not comment it again -I hate to do things twice! Well, I might comment on it if you insist in the thread below...



Comments