

Readers of this blog know that I often discuss here the latest results of searches of Supersymmetric (SUSY) particles -nowadays furthered by the CDF and DZERO experiments at the Fermilab Tevatron collider, and by the ATLAS and CMS experiments at the CERN LHC.
The game of limit-setting on SUSY parameters has been very recently taken over by the LHC experiments, which both published their first results on 35 inverse picobarns of 7-TeV proton-proton collisions. While 35/pb are less than a hundredth of the data already collected at the Tevatron, the LHC's x3.5 larger nominal center-of-mass energy is all what matters as far as producing heavy bodies is concerned (forget the difference in projectiles -hitting protons with protons or protons with antiprotons is just the same thing at these energies, since what is going on is simply that a stream of quarks and gluons hits another stream of quarks and gluons: only electroweak processes do tell the difference, but the overwhelmingly dominant strong interactions do not).
Now, it would have been quite easy to make a meta-prediction before the startup of the LHC: very soon, theoretical papers would appear, living on the constantly updating lower limits on sparticles that the new energy regime would enable. And it is in fact happening. Already a few groups have started to analyze the results of ATLAS and CMS, to produce global fits that include the new experimental information in an attempt to provide "weather forecasts" for SUSY.
I recently hosted in my blog a piece by Ben Allanach, one of the authors of such studies. In his witty guest post Ben explained how the CMS data could change the probability density functions (PDF) of sparticle masses, for instance. Of course, such PDFs only exist if SUSY is a correct theory of Nature (the bitch, not the magazine), so a sceptic could well ignore them. Well, I happen to be a sceptic of SUSY -I even bet $1000 against it a few years ago, and the bet still stands- but let us not ignore them instead. So I will just mention the publication, a few days ago, of a second study by Ben Allanach and his group.
Ben's group studied the recently published result by ATLAS in this new paper. Now, I need to make a short diversion, to explain in a tone that does not look apologetic why the ATLAS result is much more constraining than the CMS one in the space of SUSY parameters -driving Ben's interest in a quick re-analysis.
ATLAS and CMS both studied the "gold-plated" signature of SUSY at hadron colliders: missing transverse energy and hadronic jets. This signature is the most frequent outcome of the production of SUSY particles in a wide chunk of parameter space. That is because squarks and gluinos are the SUSY particles endowed with colour charge, and are thus produced most copiously in hadronic collisions. When they decay, they produce quarks and gluons, together with other sparticles that eventually decay into a lightest sparticle, the neutralino. The neutralino remains there, incapable of turning into anything lighter (we are assuming conservation of R-parity here, the quantum number that is one for SUSY particles and zero for normal particles: the lightest R=1 particle then is perfectly incapable of turning into anything else), and due to its properties it escapes the detector unseen, generating observed missing transverse energy. There you have it: missing energy and jets.
Why then, if ATLAS and CMS looked at similarly-sized datasets, and if they are similarly sensitive to jets and missing energy, did they produce significantly different results on this search ? Well, because of two things. Or maybe three. Diatriba mode on.
One: the ATLAS search was more aggressive than the CMS one. While CMS relied on a very robust variable to search for SUSY-like excesses, ATLAS used the available information more thoroughly, gaining a bit of sensitivity over CMS. Not much, just a little bit. Confidence wins over conservativeness, 1-0 for ATLAS.
Two: CMS happened to see an excess of events - a insignificant one, perfectly compatible with backgrounds; but still an excess, which made their limit on SUSY particle production rates looser than it could have been. On the other hand, ATLAS saw generally fewer events than they predicted by standard model sources alone, and this, when you are not going to be able to claim a discovery, is actually a bliss for a HEP experiment: the rate limit you get is tighter. Luck wins, 2-0 for ATLAS.
Three: ATLAS used a rather questionable method for limit setting. They somehow resurrected a frequentist method that had been abandoned 25 years ago, a method that has at least two caveats, and which produces a significantly tighter upper limit with respect to any of the three PDG-endorsed methods for limit setting. CMS resorted to the CLs method instead -which, while not the best one on the market, is indeed one of the trio of advised PDG methods. The more aggressive ATLAS method produced a tighter limit on SUSY parameters: 3-0 for ATLAS.
If you are familiar with how uncertainties add up in quadrature, or just with Brownian motion, you know that three random effects usually cancel each other. In this case, the three effects acted in concert and pulled in the same direction, and the result is that ATLAS was able to produce much tighter limits than CMS in this round of the battle.You can see it in the figure below: the ATLAS limits are in red, the CMS limits in black. Note how the ATLAS observed limit is above the expected limit: this is due to their observing fewer events than expected.

Ok, diatriba mode off. Now, about the new paper in the arxiv. The authors examine the ATLAS result in detail, and they show quite a display of patience in using all the available experimental information released by ATLAS in order to produce meaningful inputs to their global fit of SUSY parameters in the CMSSM model. Indeed, these days experiments should release their likelihoods (or similarly basic information) together with their abstracts and preprints, if they want to enable theorists to do their work. Alas, we are not yet at that point. Indeed, Ben and company spends a few pages of their article explaining how they "extrapolated" the missing information out of the data available. So one point should be drawn here: experiments, please release more information about your measurements!
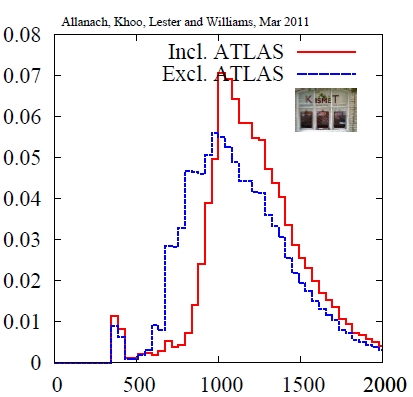 In the end, the global fit produces improved "forecasts" for the mass of sparticles, if you buy the particular version of SUSY that is of liking of the authors. For instance, let us look at the PDF of the gluino mass before and after the inclusion in global fits of the ATLAS limits (see right): the fit excluding (blue) and including (red) the new result produce a significantly different distribution, obviously shifted to higher mass. No surprise -higher gluino masses makes these particles harder to produce even in the powerful 7-TeV collisions. But fear not: the LHC will produce about 50 times more data in the next few months, and much of the available parameter space will be scanned with such large datasets.
In the end, the global fit produces improved "forecasts" for the mass of sparticles, if you buy the particular version of SUSY that is of liking of the authors. For instance, let us look at the PDF of the gluino mass before and after the inclusion in global fits of the ATLAS limits (see right): the fit excluding (blue) and including (red) the new result produce a significantly different distribution, obviously shifted to higher mass. No surprise -higher gluino masses makes these particles harder to produce even in the powerful 7-TeV collisions. But fear not: the LHC will produce about 50 times more data in the next few months, and much of the available parameter space will be scanned with such large datasets.



{kind=link}
Comments