


It's easy to get most of them correct. I used to live in Pennsylvania, for example, which was once pretty mainstream Democrat but then became among the last of a more rare "Blue Dog Democrat" state - Democrats, but not the kooky social authoritarian ban-happy New York and California kind. It was understandable because union people in Pittsburgh don't have much in common with the residents of 'Frisco except a D next to their name. Yet that changed over time too, as both parties adopted Big Tent mentalities and candidates had to match. Senator Joe Lieberman was victim to it. In his Senate re-election campaign he had to run as an Independent because he could not win a Democratic primary. He was the wrong kind of Democrat for Democrats six short years after he was their Vice-Presidential nominee. Sen. Dick Lugar fell victim to that same thinking among Republicans this year.
Pennsylvania, like California, is not in contention any more. We don't start electoral votes at 0 in 2012, we start with 190 on each side. There were supposedly 9 "battleground states" this year, which means 5 if you are not a mainstream media company that wants to keep people watching their program. As of this morning, Florida refused to declare a winner but 7 of the 8 other supposed battleground states went for President Obama, which means it was only a battleground in the eyes of the media. In reality, the polls had already shown how people were going to vote, right?
Yep, we are that polarized. Averaging polls is not all that scientific, and I was so unconvinced that this was a battle I wasn't even going to bother watching Tuesday night, but Razib Khan at Discover got me interested because he 'gamified' the election for me - by betting that the polls would be really accurate - not get the correct answer, but be accurate. We had to settle on one test of accuracy and he picked Nate Silver, who writes the 538 blog at the New York Times, because Silver averages models from lots of polls. Like I wrote in my article on the topic, 'if you look around the Poker table and can't spot the sucker, you are the sucker'.
Well, I was the sucker this year, Razib had his 50 bucks by 8 PM and I had conceded well before that. He didn't need Silver, he could have used Real Clear Politics or just about anyone else and won this bet. The only people predicting a Romney win were hopeful Republicans so that was not the issue but I could at least predict a loss for poll averaging. Statistical averaging is not science, outside of psychology. Right?
Sure, though it is academic because I am out $50. But while science media beatifies Nate Silver of the New York Times, we have to ask why, since he is not the only one who was right, he is getting more attention than people who were more right. Since Razib and I picked November 4th as our bet, Silver got 49 out of 50 - everyone else who averaged got that also.
Heck, even people betting in Europe got 49 of 50 correct, they got the same one wrong Silver did:
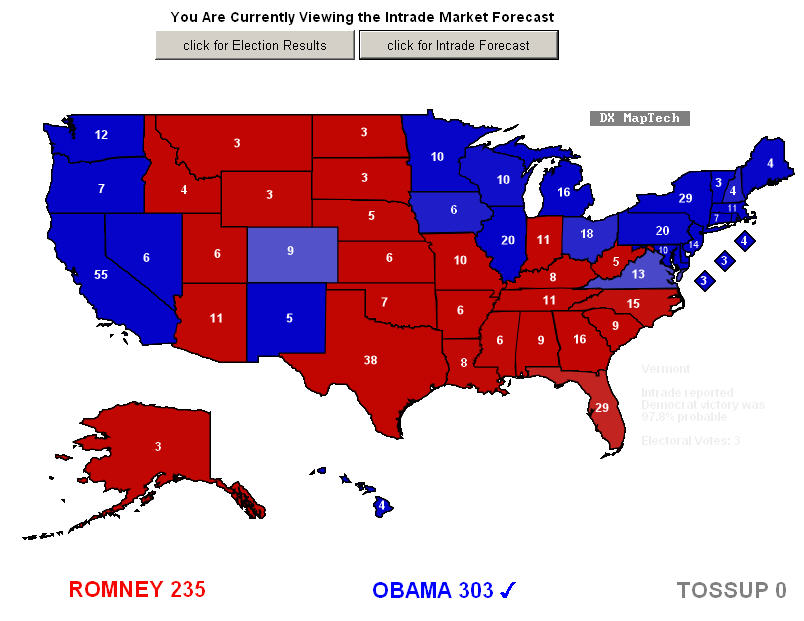
What is intriguing, and it also answers why Silver is getting such a response, is how many people are so violent about the election - not the results, no one with a clue bet against Obama, but about Nate Silver himself. They are you-insulted-my-sports-team levels of irrational because I bet against the accuracy of his model, a guy they never met who writes for a $2 billion company as opposed to independent, non-corporate-owned science media site Science 2.0, which he is regression toward the mean guaranteed to have never read or heard about.
Even though he is no more right than polls, and less right than other statisticians, people are saying he is super scientific. It looks a lot like motivated reasoning to anyone impartial.
If we want super scientific, why not extol Prof. Drew Linzer of Emory University? His votamatic nailed the electoral votes a week ago, when Nate Silver was off by a whopping 33 electoral votes. He's a political scientist. Or Prof. Sam Wang in the department of molecular biology at Princeton, who was predicting 99% for Obama and 319 electoral votes when Silver was still only at 75%. Those were predictions. Waiting until the last possible moment and predicting exactly what the polls show is not scientific wizardry, if we had bet on Tuesday instead I certainly would not have crashed my $50 plane into the aircraft carrier of reality.
And that is all that happened, the polls were right, not the model, because the election was not close. Yet people on Twitter are comparing Nate Silver to Chuck Norris as if he is, well, the Chuck Norris of statistics. Meanwhile, the poor schleps at Real Clear Politics got the same result and earn no respect at all.
Americans are polarized and that has nothing to do with science. Married people, old people, religious people and white people voted exactly as polls expected. Single people, minorities, young people and atheists voted exactly as expected.
No one's votes are in play, any more than California and Texas are up for grabs to a good candidate unless the right letter is associated with their name. That should be the concern but instead we now have villagers with pitchforks erecting cults of personality around people at the New York Times for being less right than academics. But more right than Fox News.
It turns out that the reason so many people on my Twitterfeed are genuflecting over him now is because right wing pundits had been critical of him. In other words, it has nothing to do with rationality, it is the same political gamesmanship as November 5th, another tool in the ongoing culture war. It isn't science.
If averaging polls were science, we wouldn't need to have everyone vote. In physics modeling you can assume symmetry in some parts, you can use boundary conditions and you can use parameters and you will still get the correct result. That is science. In polling, you can't do that - not yet anyway. But maybe it is coming.
In 1936, Arthur Nielsen used sampling to create a model that used a limited number of set-top devices to determine what all Americans were watching with the same accuracy as polling has today. And that was when there were only a thousand TV sets on the whole planet. It determined what we all saw and how fortunes were made and how advertisings spent money. It was a republic of media.
With modern technology, maybe we could create a model where 1,000 representative people determine elections. That would be science. Averaging a bunch of polls is not, it is just a sign that people are becoming more entrenched and so polls are more accurate - and that means we are less likely to have elections that are meaningful.



Comments