

Tom, Dick and Harry explain a statistical method.

The mysterious Voynich Manuscript.
A simple analysis of a sufficiently large text can reveal much about the topic of that text, if the language is known.
If the text, as in the case of the Voynich Manuscript, is written in an unknown script, then the same simple analytical method can point the way to the underlying language, or language group.
The method is truly simple: an ASCII text document is read by a computer program which extracts all strings of purely alphabetical characters. These strings, which may or may not be words, are stored in an array: a linked array is used to store the number of occurences of each word. The arrays are sorted by frequency and the resulting list of words and their frequencies within the document is output as a text file.
The "Tom" and "Dick" of the above subtitle refer to two very well-known books. My readers should be able to guess the names of these books from the statistics shown below,
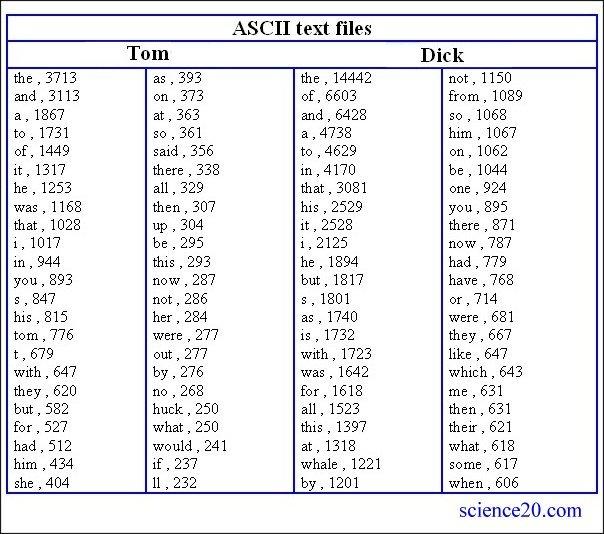
Tom and Dick
The "Harry" of the subtitle is Henri Bué, translator of a world famous children's book. It should not be difficult to guess the name of the book merely by seeing a few of the most frequent words in the translation.
de , 938
la , 815
le , 765
et , 684
elle , 569
un , 422
dit , 416
alice , 399
que , 398
en , 393
This basic form of word frequency analysis shows that for many languages the most important thing, person or topic in any suitably large text file can be rapidly discovered by running a very simple program.
The same method has been tried on many books. In all cases the name/s of the most important character/s place/s or thing/s appear in the top results, usually within a list of what may be called "grammar words".
If a text is obscured by a basic letter substitution method, those "grammar words" form a useful crib which can be used to crack the code.
The Voynich Manuscript does not permit us to find such a crib. This indicates that the underlying language uses a grammar which relies much less on "grammar words" than, say, English, French, Italian, German etc.
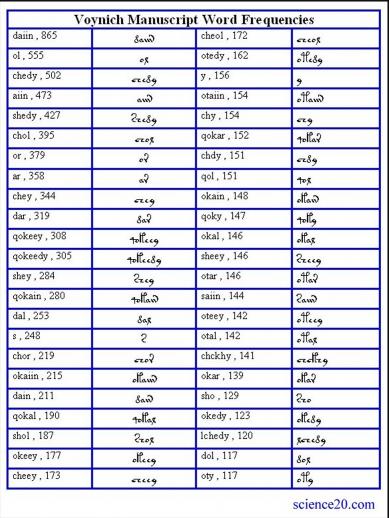
If not "grammar words", then what? Another way to demonstrate grammar in a text is to use affixes. Are there affixes in the VM? It does appear to be the case. Below is shown a list of the most common letter groupings or words in the VM. Instead of a list of different, mostly short, words we see a cluster of words of similar appearance. This suggests that similarities convey semantic information and that the differences between visually similar words convey grammatical information, especially as suffixes.
A list of over 67,000 words created by parsing 18 Latin books was used to find the most frequent word endings, which may or may not turn out to be true suffixes. Finding such frequencies in a dictionary tells us nothing about the frequency of occurence in general literature. By finding word endings in a list of word frequencies and adding together the word frequency for each word in which the string of letters is found we can discover how frequently such word endings are used across a range of topics and authors.
A computer program was used to find the frequencies in Latin of n-grams - sequences of letters - in a range of books. N-grams of 1, 2, 3 and 4 characters were listed by frequency as words (isolates) and as word-initials, medials and finals. A comparison of the most frequent Latin n-grams with the most frequent VM n-grams demonstrates that many characters group together in the same word positions in both Latin and the VM.
Lists of words by frequency readily reveal names and topics. In the case of the VM one might expect that words to do with health, baths, leaves and oil would appear high in a list of VM words by frequency. In a document about herbs and baths, one may well expect to find that words referring to leaves and oil would be of very high frequency of occurence.
Latin words relating to "leaf,leaves" generally begin with "foli". Latin words relating to oil generally begin with "ole". If the underlying language of the VM is Latin, then we must expect to find VM characters, aka glyphs, in two large groups of similar words, capable of representing Latin "ol".
To be continued ...


Comments